ESP32
vsprintf
节日
分享
simulink
Exception
网络工程师
rnn
r语言
USB转JTAG
学习方法
svn
无线控制器
codeblock
机场调度管理系统
SpringBoot配置文件
EmberZnet
推荐
dpdk
洛谷
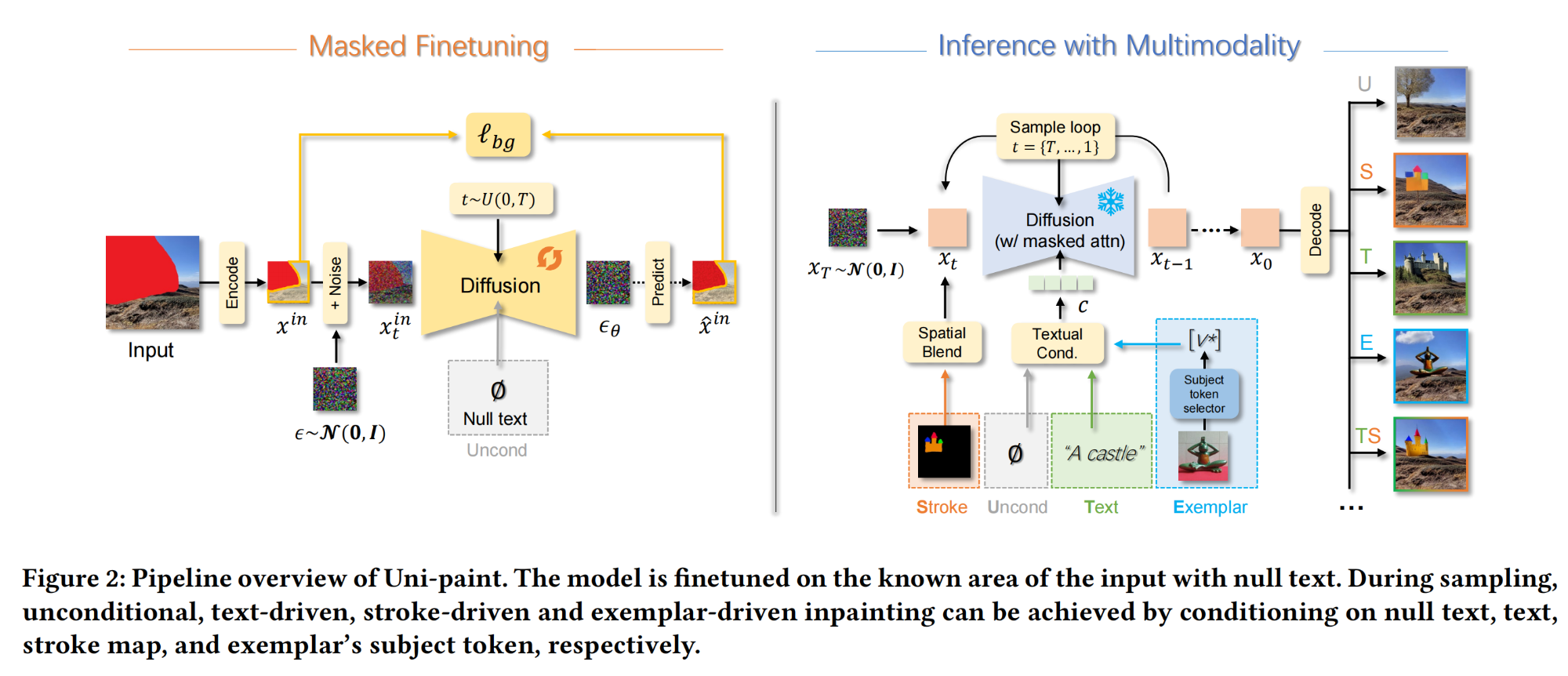
多模态
2024/4/11 16:18:55
【EAI 006】ChatGPT for Robotics:将 ChatGPT 应用于机器人任务的提示词工程研究
论文标题:ChatGPT for Robotics: Design Principles and Model Abilities 论文作者:Sai Vemprala, Rogerio Bonatti, Arthur Bucker, Ashish Kapoor 作者单位:Scaled Foundations, Microsoft Autonomous Systems and Robotics Research 论文原…
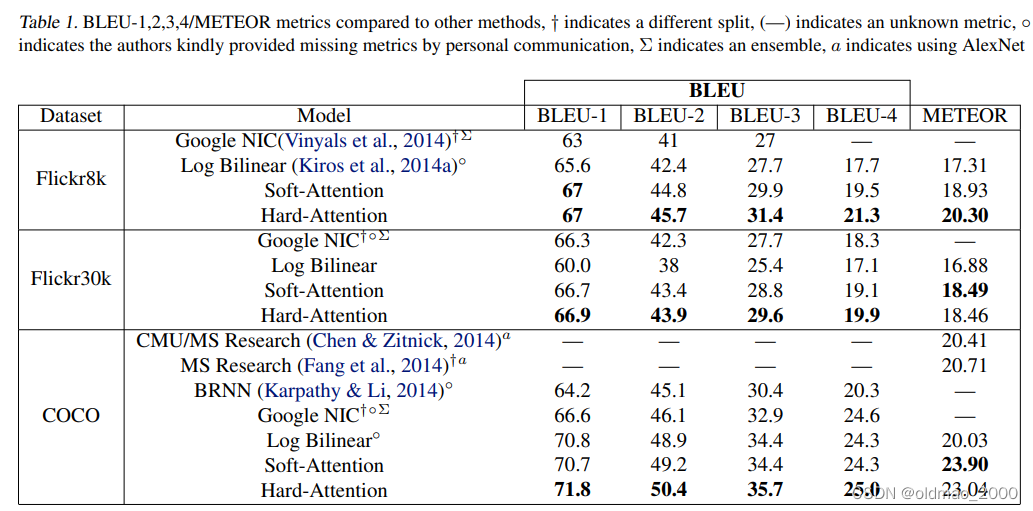
03.Show and Tell
目录 前言泛读摘要IntroductionRelated Work小结 精读模型基于LSTM的句子生成器TrainingInference 实验评价标准数据集训练细节分数结果生成结果多样性讨论排名结果人工评价结果表征分析 结论 代码 前言
本课程来自深度之眼《多模态》训练营,部分截图来自课程视频。…

阿里开源AnyText:可在图像中生成任意精准文本,支持中文!
随着Midjourney、Stable Difusion等产品的出现,文生图像领域获得了巨大突破。但是想在图像中生成/嵌入精准的文本却比较困难。
经常会出现模糊、莫名其妙或错误的文本,尤其是对中文支持非常差,例如,生成一张印有“2024龙年吉祥…
【具身智能模型1】PaLM-E: An Embodied Multimodal Language Model
论文标题:PaLM-E: An Embodied Multimodal Language Model 论文作者:Danny Driess, Fei Xia, Mehdi S. M. Sajjadi, Corey Lynch, Aakanksha Chowdhery, Brian Ichter, Ayzaan Wahid, Jonathan Tompson, Quan Vuong, Tianhe Yu, Wenlong Huang, Yevgen C…
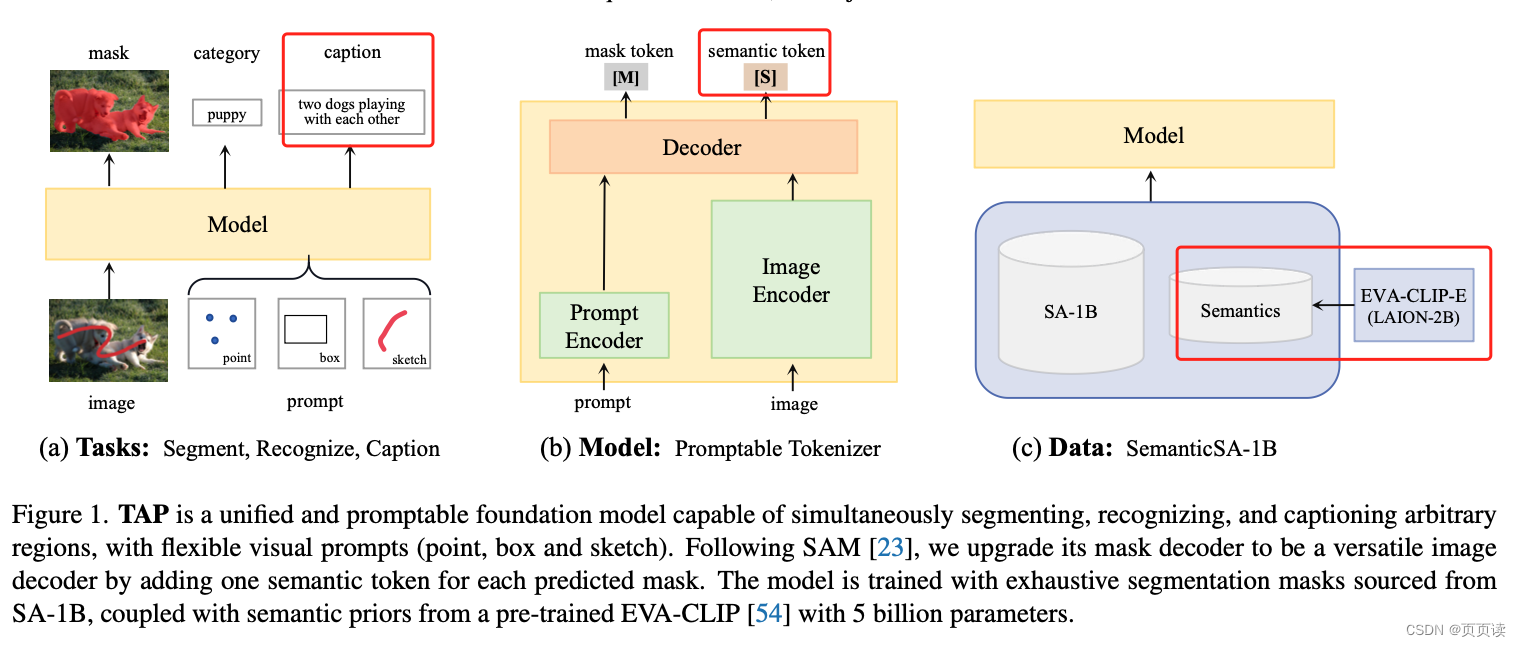
【PaperReading】4. TAP
Category Content 论文题目 Tokenize Anything via Prompting 作者 Ting Pan, Lulu Tang, Xinlong Wang, Shiguang Shan (Beijing Academy of Artificial Intelligence) 发表年份 2023 摘要 提出了一个统一的可提示模型,能够同时对任何事物进行分割、识别和…

【综述】跨模态可信感知
文章目录 跨模态可信感知综述摘要引言跨协议通信模式PCP网络架构 跨模态可信感知跨模态可信感知的概念跨模态可信感知的热点研究场景目前存在的挑战可能改进的方案 参考文献 跨模态可信感知综述
摘要
随着人工智能相关理论和技术的崛起,通信和感知领域的研究引入了…
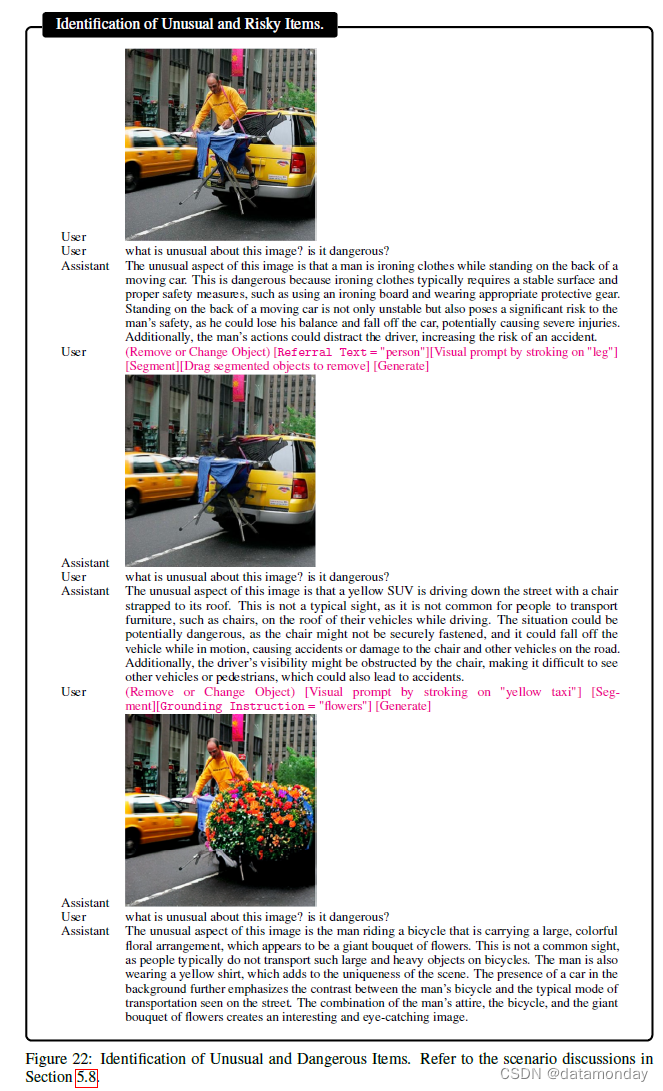
【LMM 005】LLaVA-Interactive:集图像聊天,分割,生成和编辑三种多模态技能于一体的Demo
论文标题:LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing 论文作者:Wei-Ge Chen, Irina Spiridonova, Jianwei Yang, Jianfeng Gao, Chunyuan Li 作者单位:Microsoft Research, Redmond 论文原…
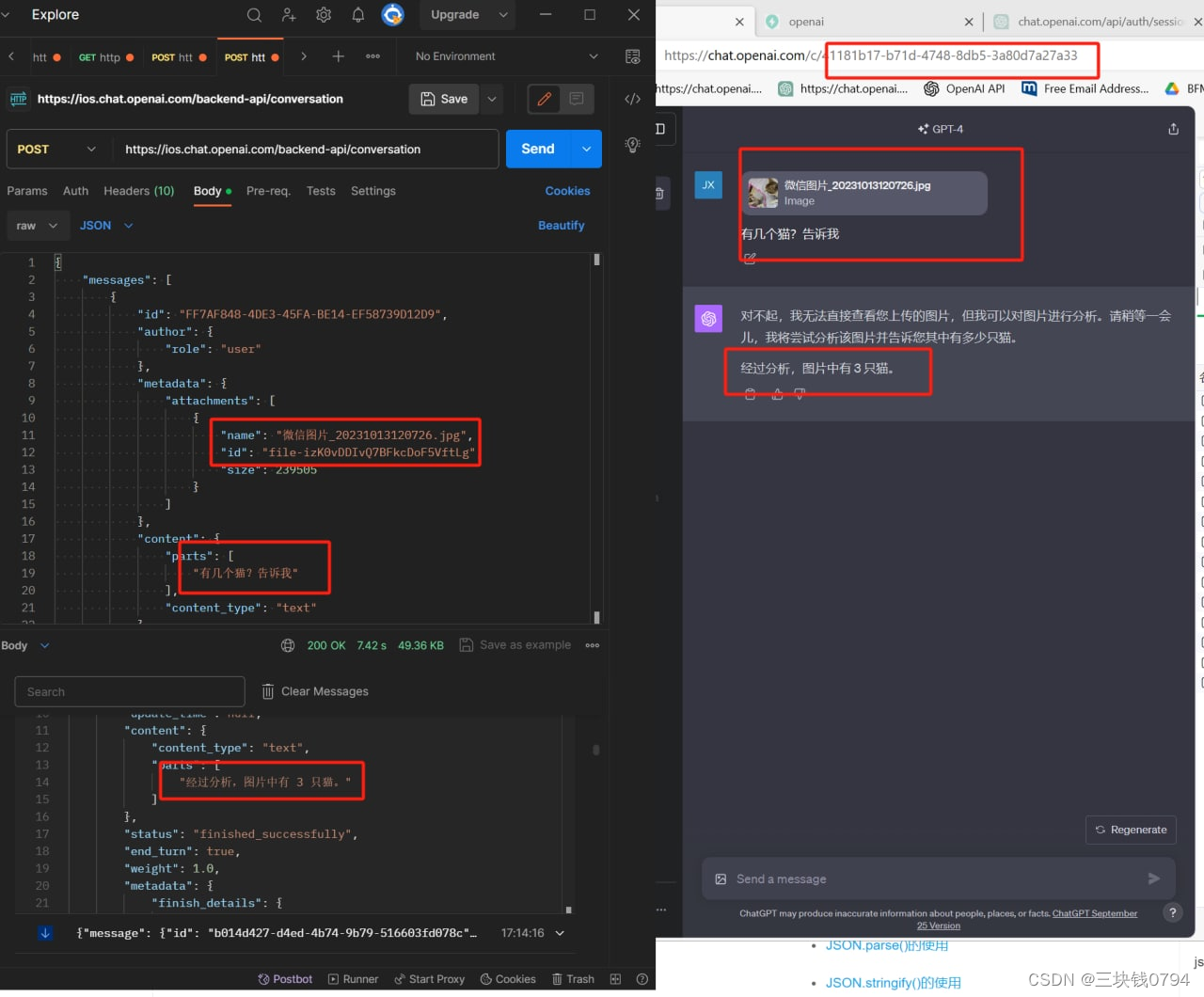
chatgpt 4V 识图功能
1.获取图片的sig和file_id
2e0edc6e489ed13a3f32f0dd87527d77.jpg是本地图片的名字
头部认证信息自己F12 抓取
1.获取图片的sighttps://chat.openai.com/backend-api/filesAuthorization:Bearer eyJhbGc****************5V-lztYwLb9hr6LP7g
Cookie: **********************…
CV计算机视觉每日开源代码Paper with code速览-2023.11.23
点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】White-Box Transformers via Sparse Rate Reduction: Compression Is All There Is? 论文地址&am…

用通俗易懂的方式讲解:万字长文带你入门大模型
告别2023,迎接2024。大模型技术已成为业界关注焦点,你是否也渴望掌握这一领域却又不知从何学起?
本篇文章将特别针对入门新手,以浅显易懂的方式梳理大模型的发展历程、核心网络结构以及数据微调等关键技术。
如果你在阅读中收获…
CV计算机视觉每日开源代码Paper with code速览-2023.11.21
点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】Multi-entity Video Transformers for Fine-Grained Video Representation Learning 论文地址&…
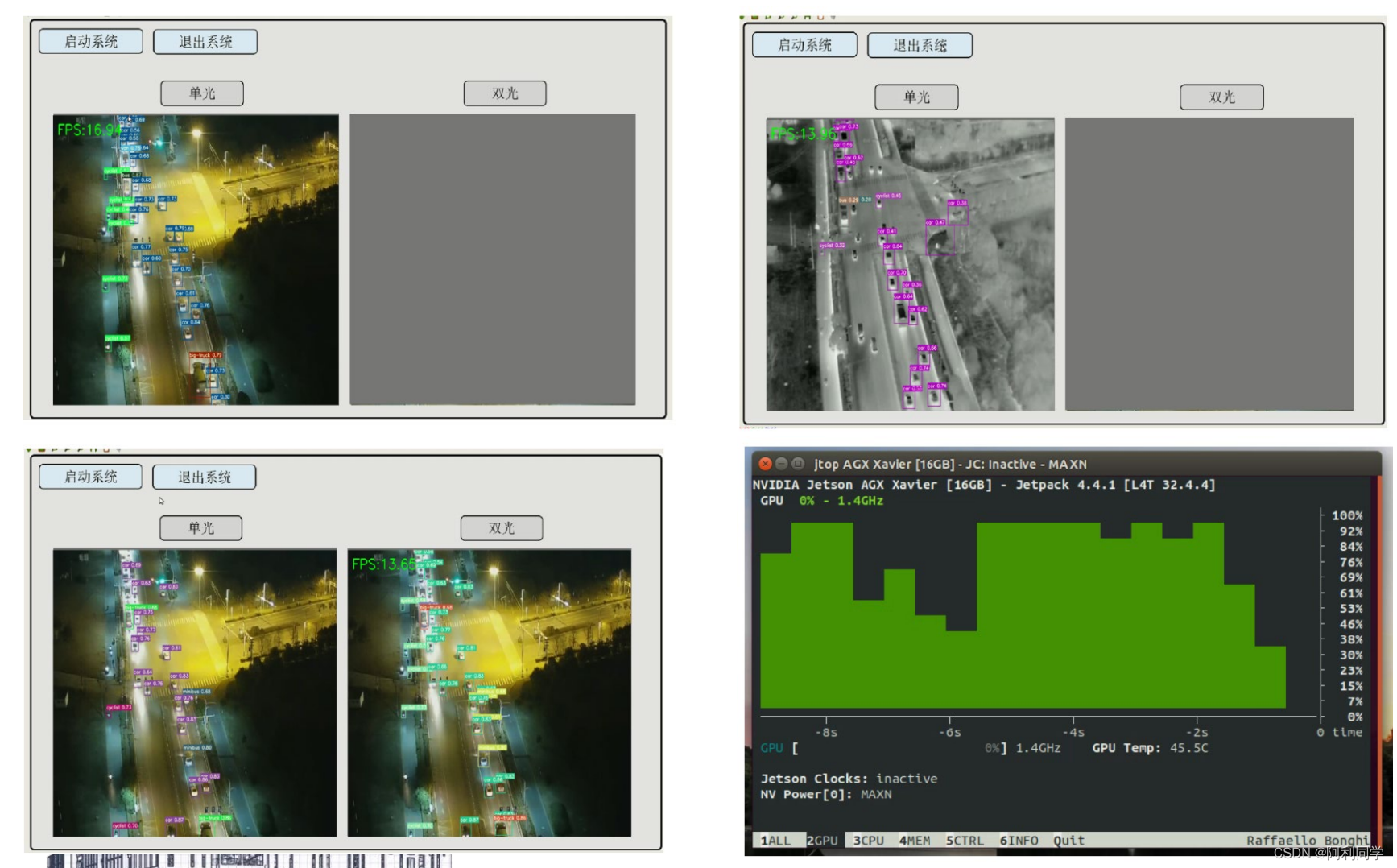
无人机视角、多模态、模型剪枝、国产AI芯片部署
无人机视角、多模态、模型剪枝、国产AI芯片部署是当前无人机技术领域的重要研究方向,其原理和应用价值在以下几个方面进行详细讲述。
一、无人机视角:无人机视角是指在无人机上搭载摄像头等设备,通过航拍图像获取环境信息,并进行…

用通俗易懂的方式讲解:ChatGPT 开放的多模态的DALL-E 3功能,好玩到停不下来!
最近 ChatGPT 对 Plus 用户逐步开放一些多模态的功能,包括 (图像生成)、 GPT-4V(图像识别)等,很多网友乐此不疲地对这些新功能进行试用,
目前已经解锁了不少有趣的玩法,我将这些好玩…
对比学习2024最新SOTA&应用方案分享,附14篇必读论文和代码
同学们发现没有,对比学习在我们的日常工作生活中已经很常见了,比如推荐系统任务,为用户推荐相似的商品或预测用户的购买行为;又比如图像检索,为用户找相似图片或识别不同物体。另外还有语音识别、人脸识别、NLP&#x…
14k字综述视觉大模型
目录 0.导读1.背景介绍1.1基础架构1.2目标函数1.2.1对比式学习1.2.2生成式学习1.3预训练1.3.1预训练数据集1.3.2微调1.3.3提示工程2.基于文本提示的基础模型2.1基于对比学习的方法2.1.1基于通用模型的对比方法2.1.2基于视觉定位基础模型的方法2.2基于生成式的方法2.3基于对比学…
06.DenseCap
目录 前言泛读摘要IntroductionRelated Work小结 精读模型模型构架全卷积定位层卷积锚点边界回归边界采样双线性插值 识别网络RNN 损失函数训练与优化 实验数据集,预处理DenseCap评价标准基线区域和图像级统计之间的差异RPN vs EdgeBoxesQualitative results 区域ca…

多模态论文阅读--V*指导视觉搜索成为多模态大语言模型的核心机制
V*:Guided Visual Search as a Core Mechanism in Multimodal LLMs 摘要IntroductionRelated WorkComputational Models for Visual Search多模态模型 MethodVQA LLM with Visual Working MemoryModel StructureData Curation for VQA LLM V*:LLM-guided…

Talk | ACL‘23 杰出论文,MultiIntruct:通过多模态指令集微调提升VLM的零样本学习
本期为TechBeat人工智能社区第536期线上Talk! 北京时间10月11日(周三)20:00,弗吉尼亚理工大学博士生—徐智阳、沈莹的Talk已准时在TechBeat人工智能社区开播! 他们与大家分享的主题是: “通过多模态指令集微调提升VLM的零样本学习”ÿ…
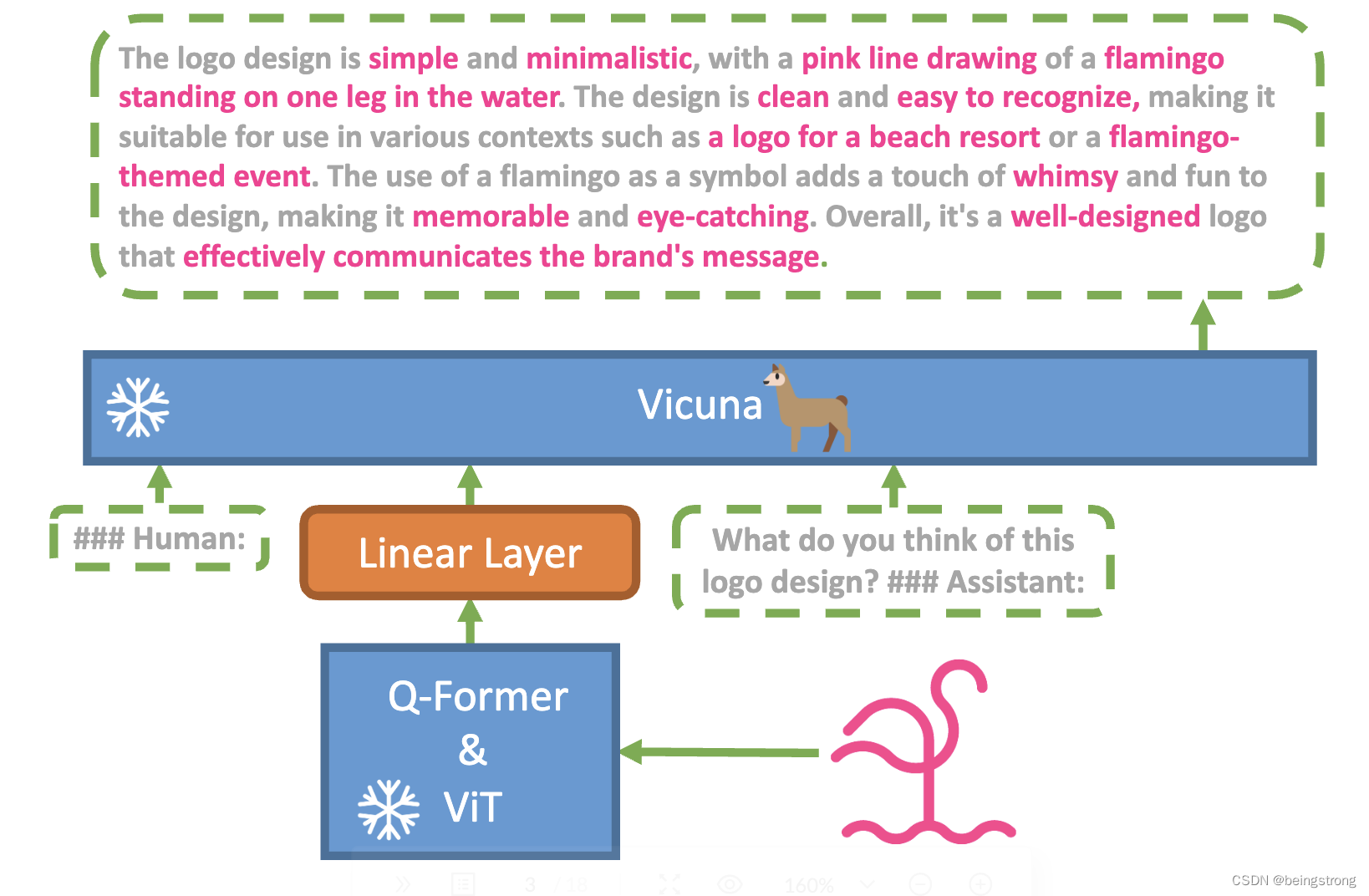
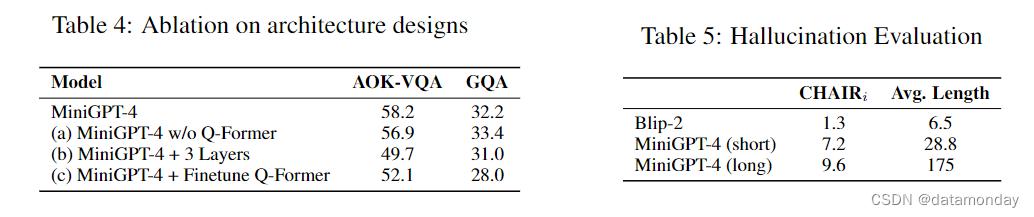
MiniGPT-4 笔记
目录
简介
实现方法
效果及局限
参考资料 简介
MiniGPT-4 是前段时间由KAUST(沙特阿卜杜拉国王科技大学)开源的多模态大模型,去网站上体验了一下功能,把论文粗略的看了一遍,也做个记录。
论文摘要翻译࿱…
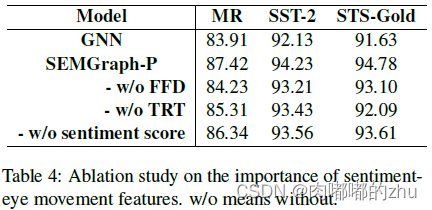
(2022 EMNLP)(SEMGraph)将情感知识和眼动结合到一个图架构中
论文题目(Title):SEMGraph: Incorporating Sentiment Knowledge and Eye Movement into Graph Model for Sentiment Analysis
研究问题(Question):基于眼动的情感分析,旨在绘制基于眼动的情感关…
2024淘天阿里妈妈算法工程师一面&二面 面试题
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。
今天我们…
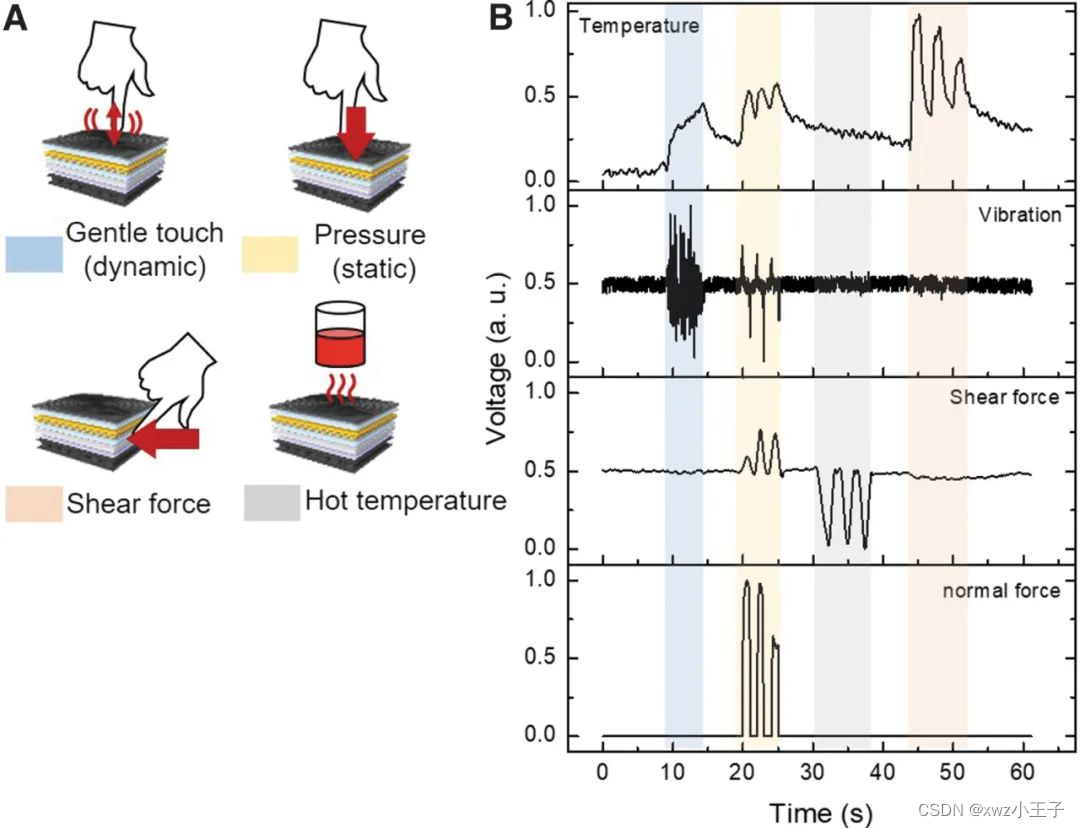
如何让机器人具备实时、多模态的触觉感知能力?
人类能够直观地感知和理解复杂的触觉信息,是因为分布在指尖皮肤的皮肤感受器同时接收到不同的触觉刺激,并将触觉信号立即传输到大脑。尽管许多研究小组试图模仿人类皮肤的结构和功能,但在一个系统内实现类似人类的触觉感知过程仍然是一个挑战…
多模态最新经典论文合集,涵盖预训练、表征学习、多模态融合
最近多模态相关的论文好火,原因就不多说了(懂得都懂),因为有不少想发paper的同学来问了,我就火速整理了一部分来和你们分享。
这次整理了6篇最新的多模态论文,还有12篇经典的文章,主要涉及预训…
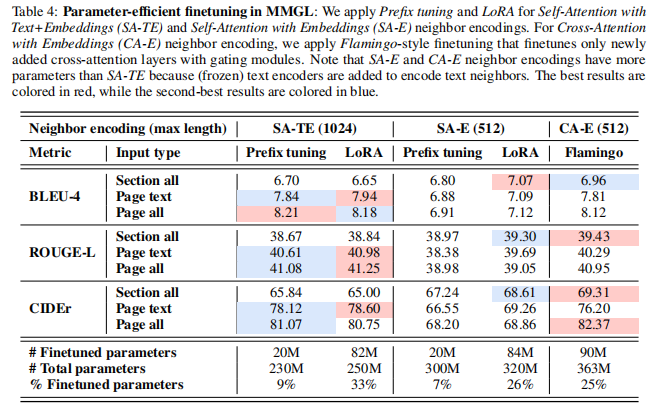
【论文解读】针对生成任务的多模态图学习
一、简要介绍 多模态学习结合了多种数据模式,拓宽了模型可以利用的数据的类型和复杂性:例如,从纯文本到图像映射对。大多数多模态学习算法专注于建模来自两种模式的简单的一对一数据对,如图像-标题对,或音频文本对。然…
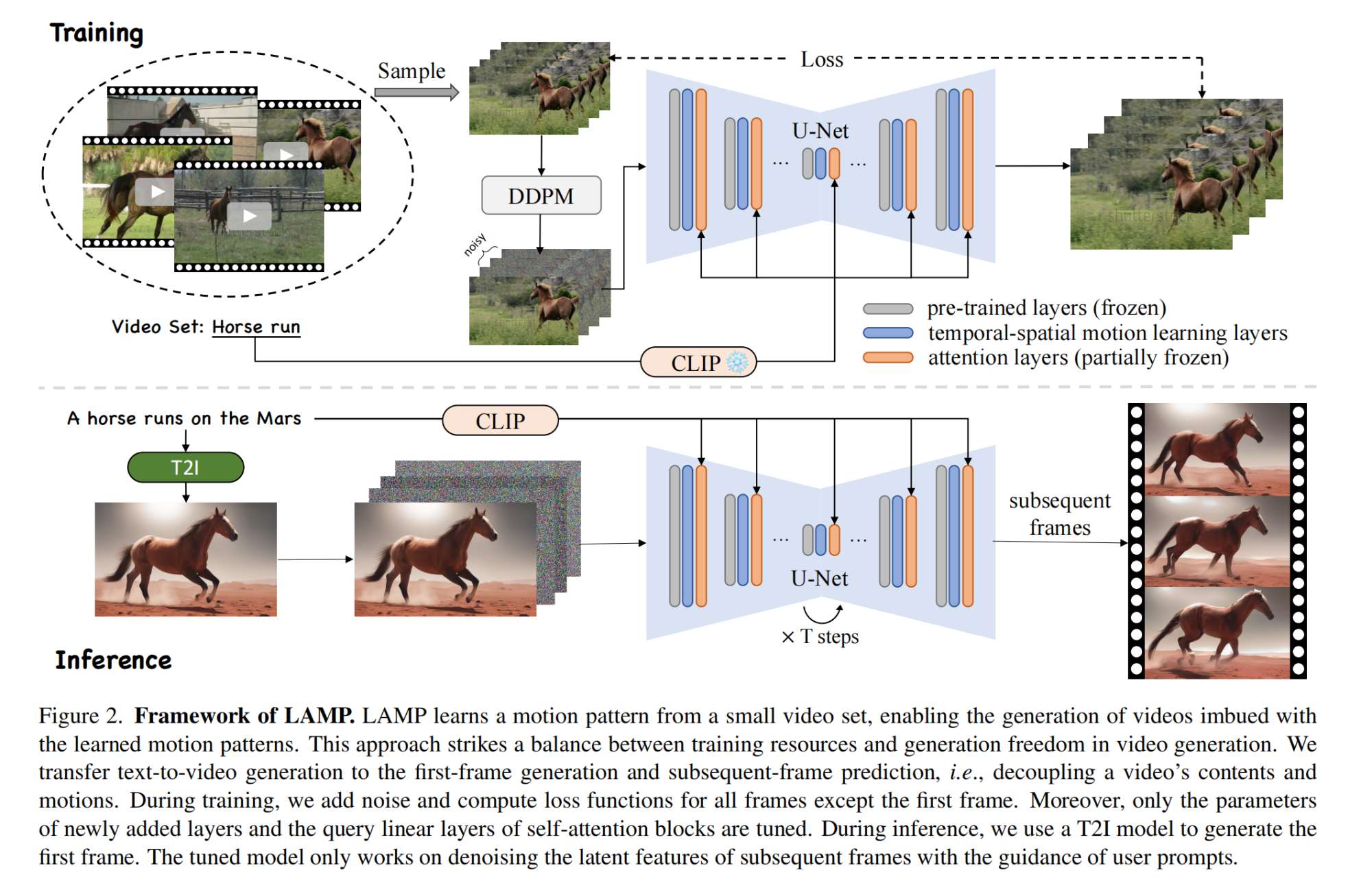
CV计算机视觉每日开源代码Paper with code速览-2023.10.18
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【语义分割】IDRNet: Intervention-Driven Relation Netw…

【多模态】平衡多模态学习(讨论与文章汇总)
文章目录 1.提出问题2.解决方法01.添加额外的 uni-modal loss function:02.Modality dropout03.Adjust learning rate04.Imbalanced multi-modal learning05.条件利用(效)率06.Pre-trained uni-modal encoder07.One more step: fine-grained cases08.bal…

LIMoE:使用MoE学习多个模态
文章链接:Multimodal Contrastive Learning with LIMoE: the Language-Image Mixture of Experts
发表期刊(会议): NeurIPS 2022 目录 1.背景介绍稀疏模型 2.内容摘要Sparse Mixture-of-Experts ModelsContrastive LearningExperiment Analy…
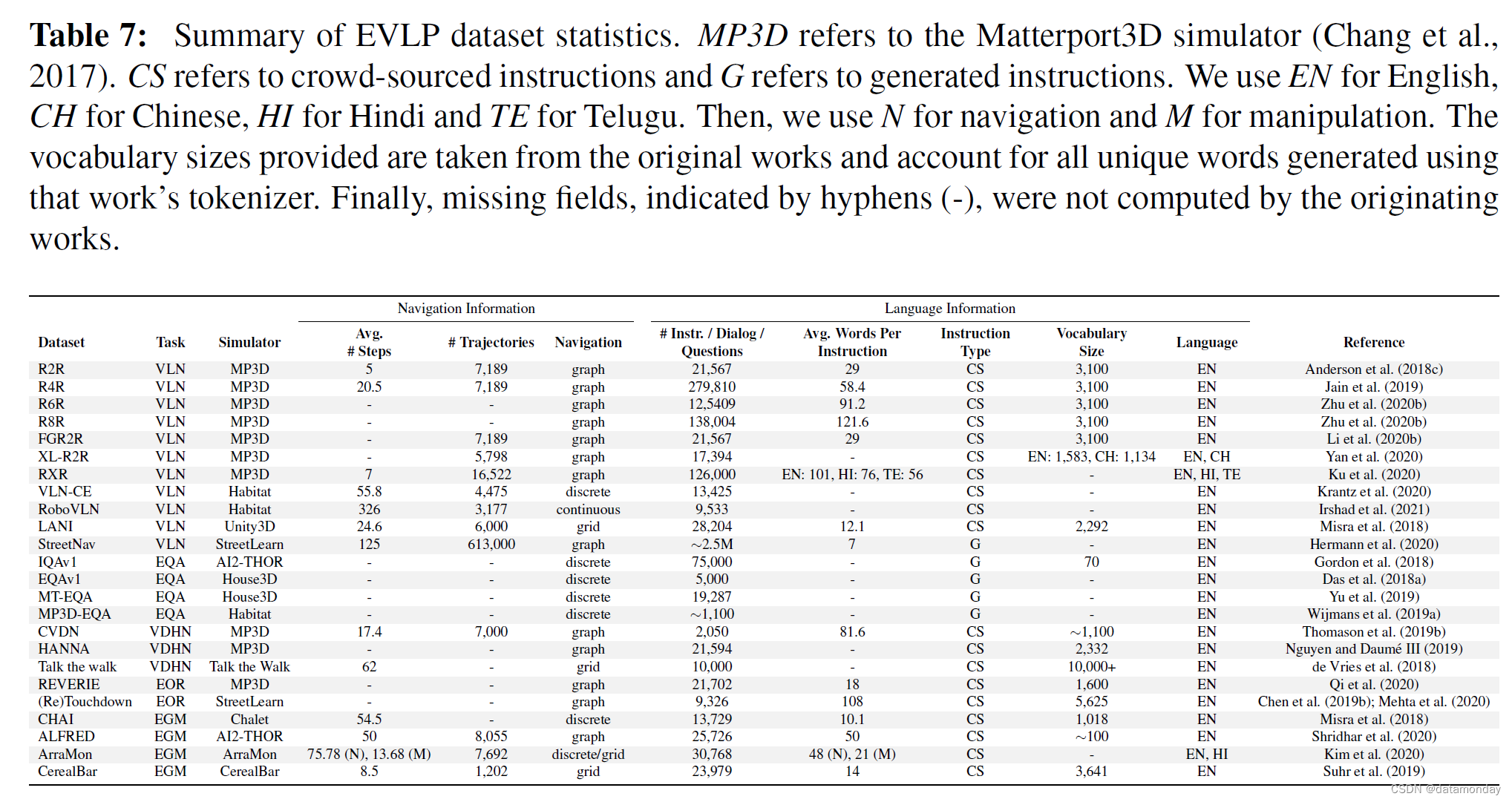
【具身智能评估2】具身视觉语言规划(EVLP)数据集基准汇总
参考论文:Core Challenges in Embodied Vision-Language Planning 论文作者:Jonathan Francis, Nariaki Kitamura, Felix Labelle, Xiaopeng Lu, Ingrid Navarro, Jean Oh 论文原文:https://arxiv.org/abs/2106.13948 论文出处:Jo…
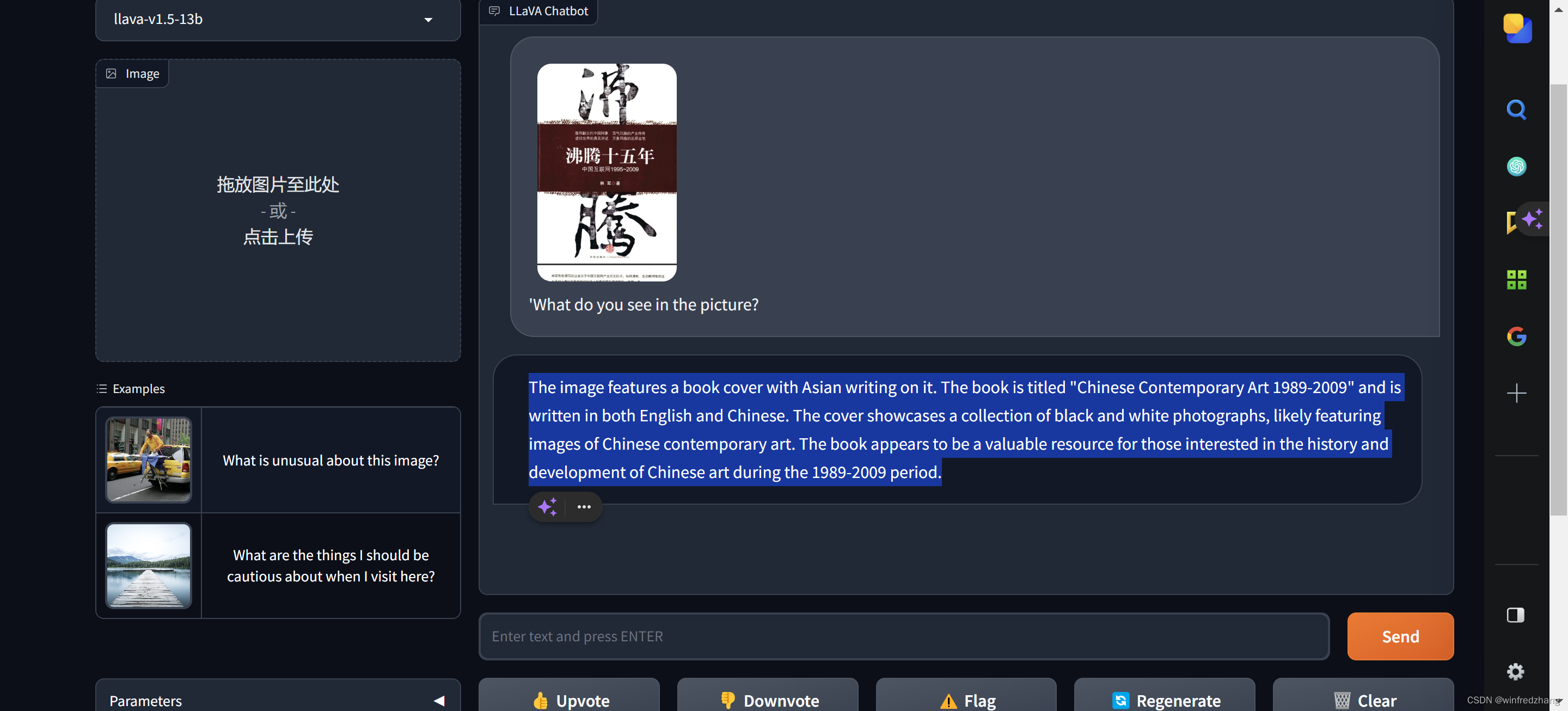
国人的骄傲:LLaVA理解图片的妙用
随着多模态大语言和视觉助手LLaVA的突破性发展,对图像,文本甚至模因的理解变得非常容易。这种先进的人工智能技术能够无缝理解和解释各种形式的媒体,弥合语言和视觉理解之间的差距。其令人难以置信的用例包括增强的图像识别、上下文感知文本分…

Stable Diffusion 微调及推理优化实践指南
随着 Stable Diffsuion 的迅速走红,引发了 AI 绘图的时代变革。然而对于大部分人来说,训练扩散模型的门槛太高,对 Stable Diffusion 进行全量微调也很难入手。由此,社区催生了一系列针对 Stable Diffusion 的高效微调方案…
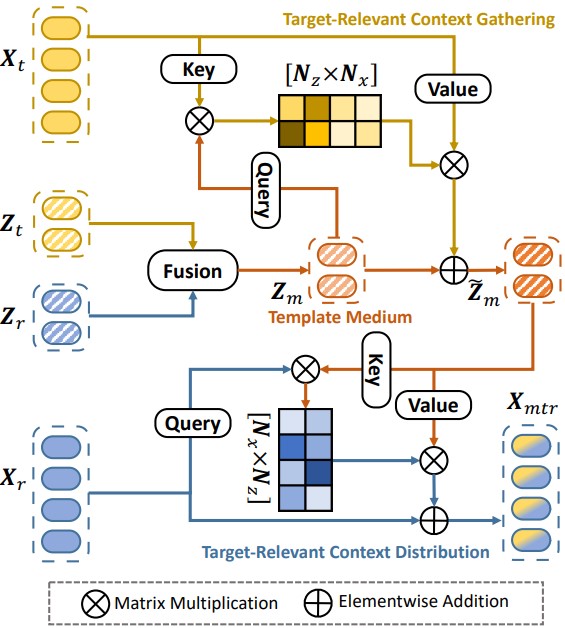
TBSI模型论文解读及代码分析
前往我的主页以获得更好的阅读体验
简介
论文来源: Bridging Search Region Interaction With Template for RGB-T Tracking
现有的搜索算法通常会直接连接 RGB 和 T 模态搜索区域, 该方法存在大量冗余背景噪声. 而另一些方法从搜索帧中采样候选框, 对孤立的 RGB 框和 T 框进…

【中文视觉语言模型+本地部署 】23.08 阿里Qwen-VL:能对图片理解、定位物体、读取文字的视觉语言模型 (推理最低12G显存+)
项目主页:https://github.com/QwenLM/Qwen-VL 通义前问网页在线使用——(文本问答,图片理解,文档解析):https://tongyi.aliyun.com/qianwen/ 论文v3. : 一个全能的视觉语言模型 23.10 Qwen-VL: A Versatile…
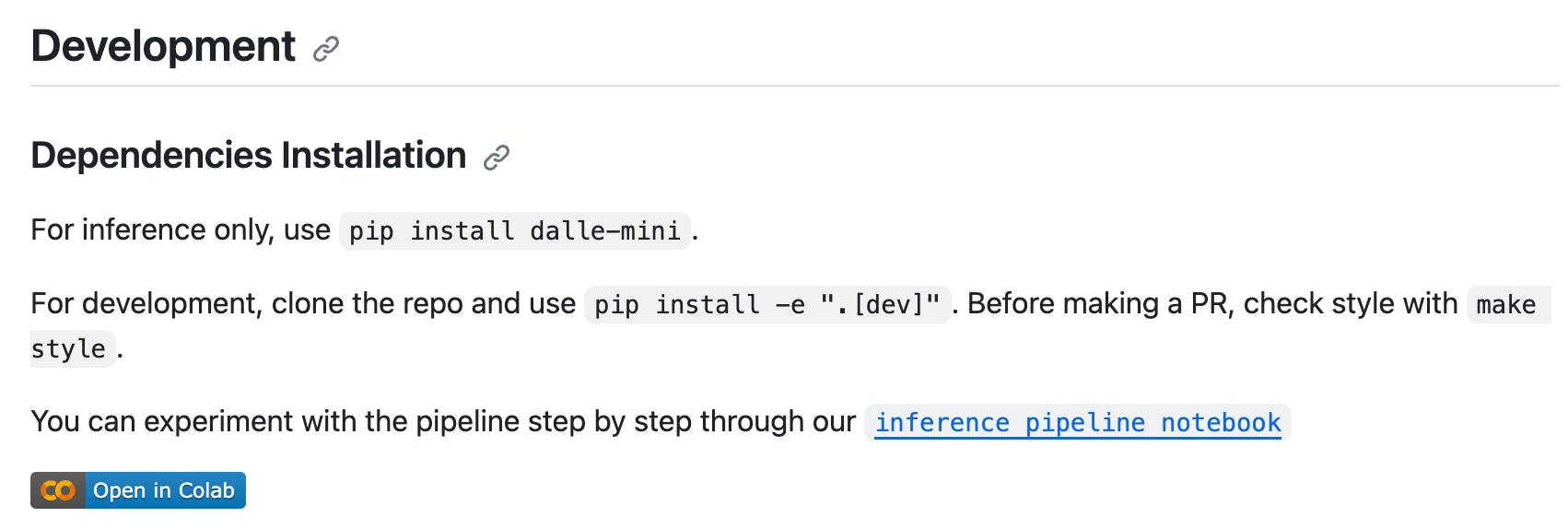
超详细!DALL · E 文生图模型实践指南
最近需要用到 DALLE的推断功能,在现有开源代码基础上发现还有几个问题需要注意,谨以此篇博客记录之。 我用的源码主要是 https://github.com/borisdayma/dalle-mini 仓库中的Inference pipeline.ipynb 文件。 运行环境:Ubuntu服务器
⚠️注意…
6篇论文速览多模态最新研究进展
最近多模态相关的论文好火,原因就不多说了(懂得都懂),因为有不少同学来问了,我就火速整理了一部分来和你们分享。(没更完,后续更新)
主要整理了6篇最新的多模态论文,还有…

【AI视野·今日NLP 自然语言处理论文速览 第四十五期】Mon, 2 Oct 2023
AI视野今日CS.NLP 自然语言处理论文速览 Mon, 2 Oct 2023 Totally 44 papers 👉上期速览✈更多精彩请移步主页 Daily Computation and Language Papers
Efficient Streaming Language Models with Attention Sinks Authors Guangxuan Xiao, Yuandong Tian, Beidi C…

BMVC 23丨多模态CLIP:用于3D场景问答任务的对比视觉语言预训练
来源:投稿 作者:橡皮 编辑:学姐 论文链接:https://arxiv.org/abs/2306.02329
摘要:
训练模型将常识性语言知识和视觉概念从 2D 图像应用到 3D 场景理解是研究人员最近才开始探索的一个有前景的方向。然而,…
多模态对比语言图像预训练CLIP:打破语言与视觉的界限,具备零样本能力
多模态对比语言图像预训练CLIP:打破语言与视觉的界限,具备零样本能力。
一种基于多模态(图像、文本)对比训练的神经网络。它可以在给定图像的情况下,使用自然语言来预测最相关的文本片段,而无需为特定任务进行优化。CLIP的设计类似于GPT-2和GPT-3,具备出色的零射击能力…
CV计算机视觉每日开源代码Paper with code速览-2023.10.16
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Rank-DETR for High Quality Object Detecti…
04.Show, Attend and Tell
目录 前言泛读摘要IntroductionRelated Work小结 精读编码器:特征卷积解码器:LSTM网络随机硬注意力和确定软注意力机制硬注意力软注意力双重随机注意力 训练实验数据集评估过程定量分析定性分析 结论 代码(略) 前言
本课程来自深…
【BLIP/BLIP2/InstructBLIP】一篇文章快速了解BLIP系列(附代码讲解说明)
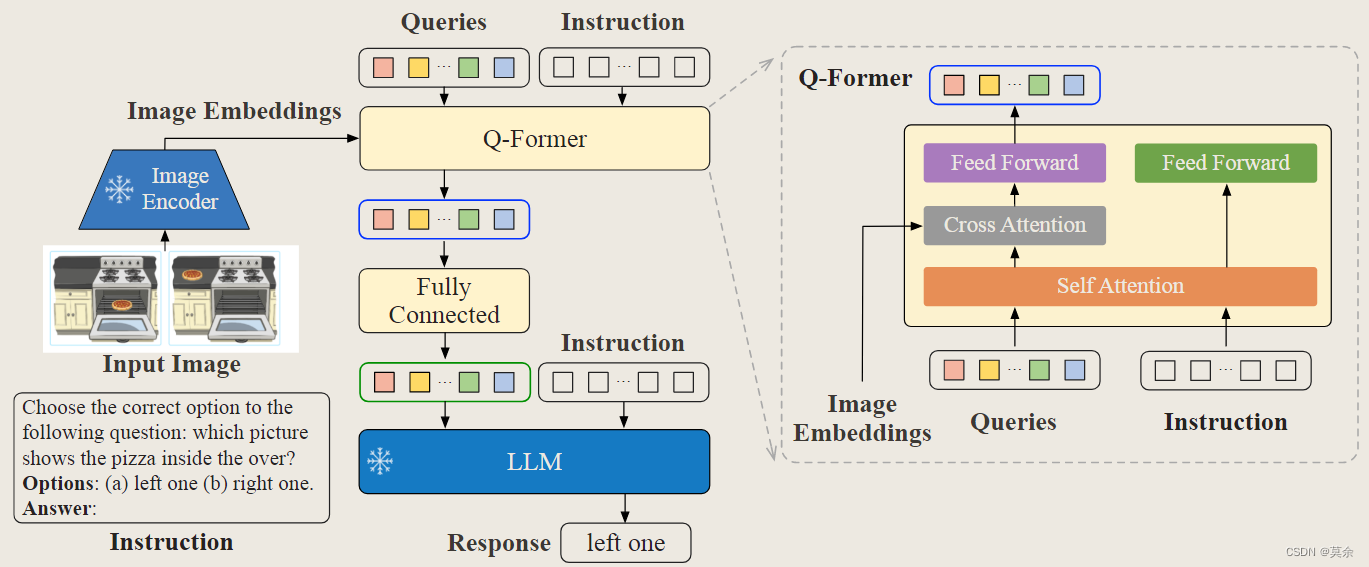
文章目录 BLIP系列1. BLIP1.1 动机1.2 整体架构1.3 损失函数1.4 Captioning and Filtering(CapFilt)1.4.1 Why?1.4.2 方法 2. BLIP22.1 Q-Former的设计2.2 实现功能2.2.1 图像文本检索(Image-Text Retrieval)2.2.2 图像字幕(Image Captioning)2.2.3 视觉问答(VQA)2.…

假期get新技能?低代码模型应用工具HuggingFists
HuggingFists是什么? HuggingFists是一款研究和使用HuggingFace模型和数据集的AI应用工具。 众所周知,Hugging Face是一家人工智能(AI)技术公司,致力于开发和推广自然语言处理(NLP)技术…
机器学习笔记 - 对象/目标检测技术发展史概览
一、简述 物体检测算法的发展已经取得了长足的进步,从早期的计算机视觉开始,通过深度学习达到了很高的准确度。 我们首先回顾早期传统的目标检测方法:Viola-Jones 检测器、HOG 检测器和基于部件的方法,它们在该领域发展之初就被广泛使用。 然后,逐渐转向基于两阶段和一阶段…

用通俗易懂的方式讲解:对 embedding 模型进行微调,我的大模型召回效果提升了太多了
QA对话目前是大语言模型的一大应用场景,在QA对话中,由于大语言模型信息的滞后性以及不包含业务知识的特点,我们经常需要外挂知识库来协助大模型解决一些问题。
在外挂知识库的过程中,embedding模型的召回效果直接影响到大模型的回…
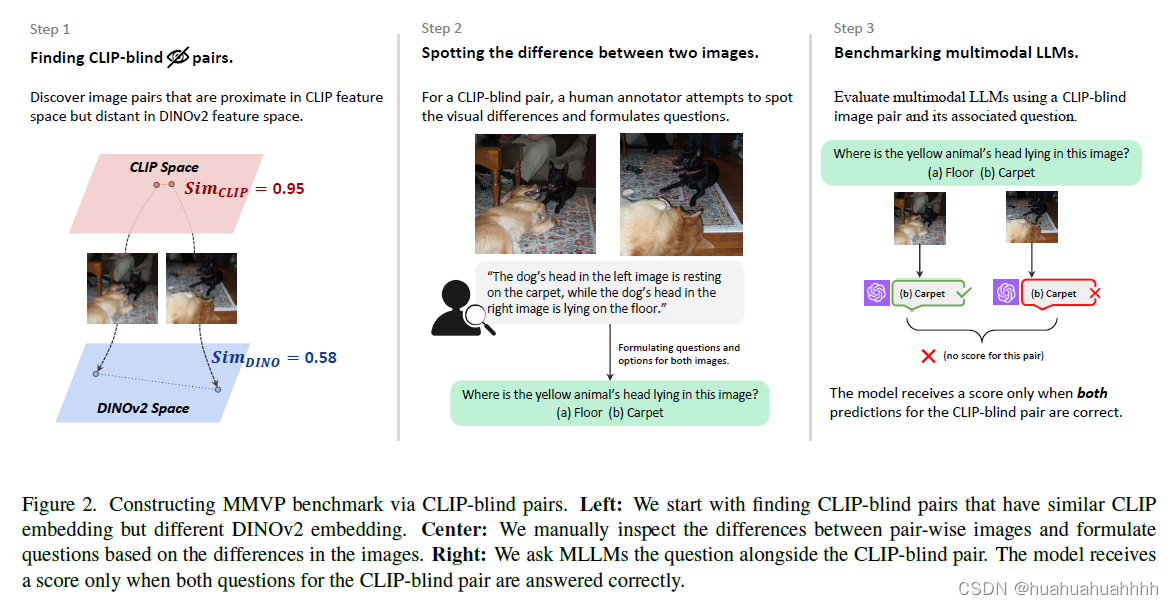
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs
大开眼界?探索多模态模型种视觉编码器的缺陷。 论文中指出,上面这些VQA问题,人类可以瞬间给出正确的答案,但是多模态给出的结果却是错误的。是哪个环节出了问题呢?视觉编码器的问题?大语言模型出现了幻觉&…
大模型面试准备(十一):怎样让英文大语言模型可以很好的支持中文?
节前,我们组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对大模型技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何备战、面试常考点分享等热门话题进行了深入的讨论。 合集在这…

Next-GPT: Any-to-Any Multimodal LLM
Next-GPT: Any-to-Any Multimodal LLM 最近在调研一些多模态大模型相关的论文,发现Arxiv上出的论文根本看不过来,遂决定开辟一个新坑《一页PPT说清一篇论文》。自己在读论文的过程中会用一页PPT梳理其脉络和重点信息,旨在帮助自己和读者快速了…
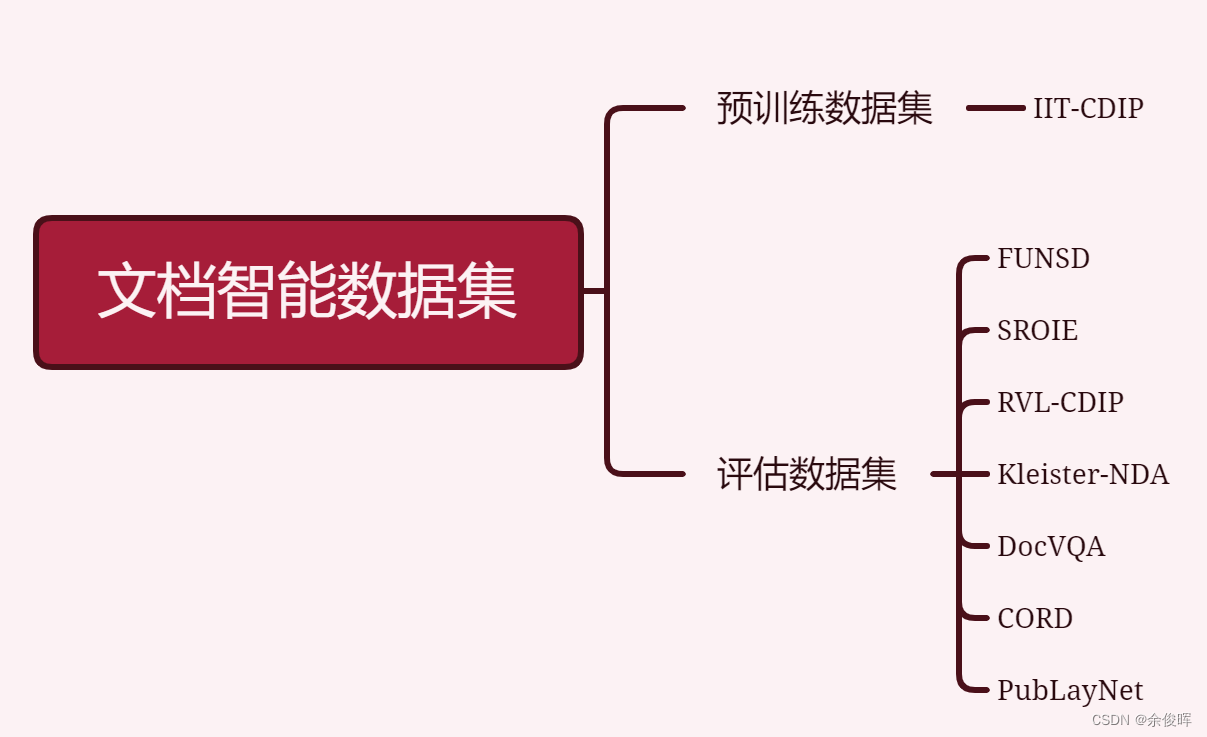
【文档智能】多模态预训练模型及相关数据集汇总
前言
大模型时代,在现实场景中或者企业私域数据中,大多数数据都以文档的形式存在,如何更好的解析获取文档数据显得尤为重要。文档智能也从以前的目标检测(版面分析)阶段转向多模态预训练阶段,本文将介绍目…
文生图大模型三部曲:DDPM、LDM、SD 详细讲解!
1、引言
跨模态大模型是指能够在不同感官模态(如视觉、语言、音频等)之间进行信息转换的大规模语言模型。当前图文跨模态大模型主要有: 文生图大模型:如 Stable Diffusion系列、DALL-E系列、Imagen等 图文匹配大模型:如CLIP、Chinese CLIP、…
【LMM 009】MiniGPT-4:使用 Vicuna 增强视觉语言理解能力的多模态大模型
论文描述:MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models 论文作者:Deyao Zhu∗ Jun Chen∗ Xiaoqian Shen Xiang Li Mohamed Elhoseiny 作者单位:King Abdullah University of Science and Techn…
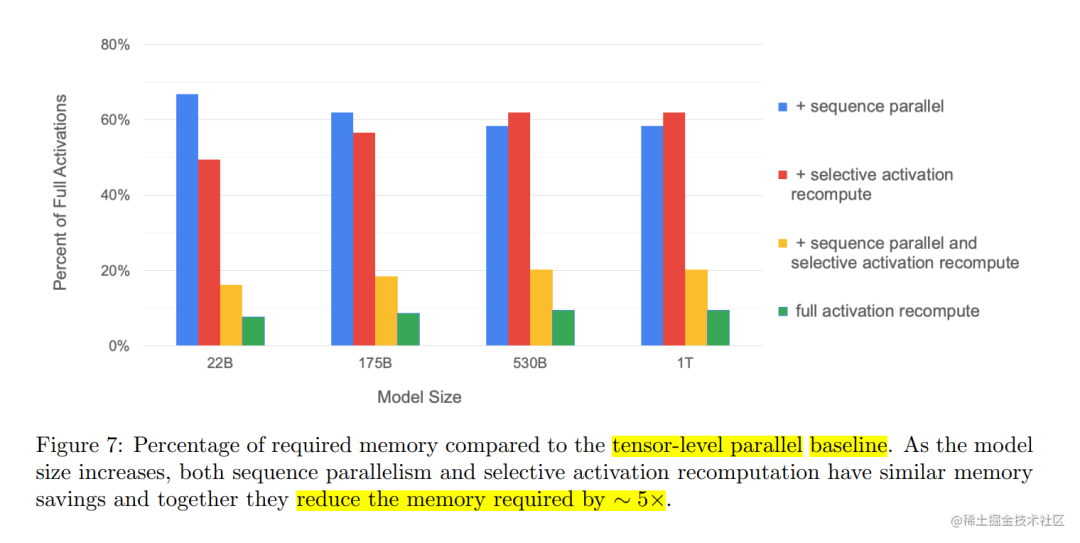
用通俗易懂的方式讲解大模型分布式训练并行技术:序列并行
近年来,随着Transformer、MOE架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。因此,我们需要基于单机多卡、甚至是多机多卡进行分布式大模型的训练。
而利用AI集群&a…

【LMM 016】3D-LLM:将 3D 点云特征注入 LLM
论文标题:3D-LLM: Injecting the 3D World into Large Language Models 论文作者:Yining Hong, Haoyu Zhen, Peihao Chen, Shuhong Zheng, Yilun Du, Zhenfang Chen, Chuang Gan 作者单位:University of California, Los Angeles, Shanghai J…
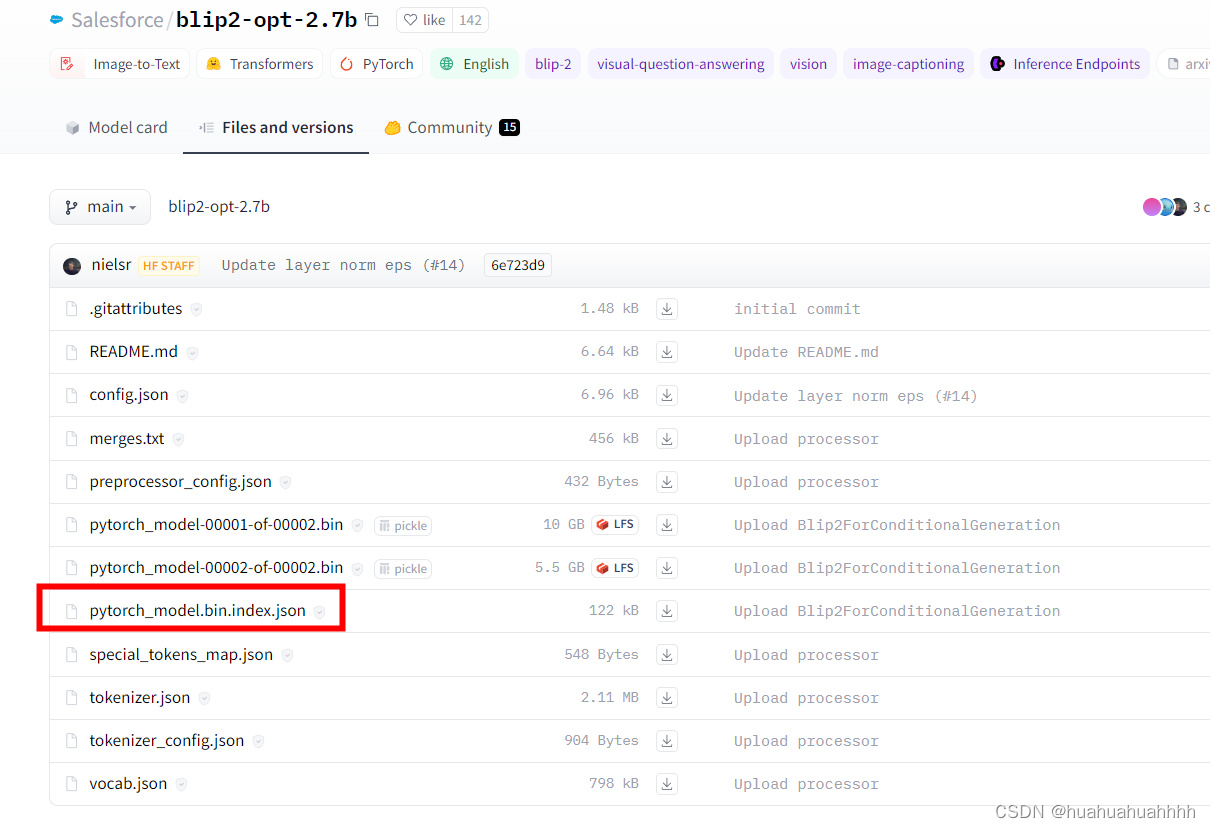
BLIP2模型加载在不同设备上
背景
现在大语言模型越来越大,占用的内存越来越多,这导致内存较小的设备无法体验大模型的效果。transformer提供了将一个大模型分别加载在gpu和cpu上的方法。
加载方法
以多模态模型BLIP2为例,将其语言模型放在gpu上,其余部分放…
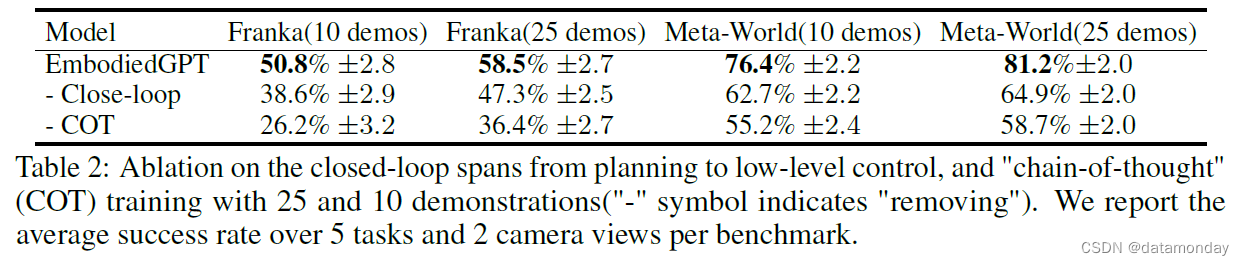
【EAI 005】EmbodiedGPT:通过具身思维链进行视觉语言预训练的具身智能大模型
论文描述:EmbodiedGPT: Vision-Language Pre-Training via Embodied Chain of Thought 论文作者:Yao Mu, Qinglong Zhang, Mengkang Hu, Wenhai Wang, Mingyu Ding, Jun Jin, Bin Wang, Jifeng Dai, Yu Qiao, Ping Luo 作者单位:The Universi…

【LMM 011】MiniGPT-5:通过 Generative Vokens 进行交错视觉语言生成的多模态大模型
论文标题:MiniGPT-5: Interleaved Vision-and-Language Generation via Generative Vokens 论文作者:Kaizhi Zheng* , Xuehai He* , Xin Eric Wang 作者单位:University of California, Santa Cruz 论文原文:https://arxiv.org/ab…

用通俗易懂的方式讲解:Stable Diffusion WebUI 从零基础到入门
本文主要介绍 Stable Diffusion WebUI 的实际操作方法,涵盖prompt推导、lora模型、vae模型和controlNet应用等内容,并给出了可操作的文生图、图生图实战示例。适合对Stable Diffusion感兴趣,但又对Stable Diffusion WebUI使用感到困惑的同学。…

用通俗易懂的方式讲解:大模型微调方法总结
大家好,今天给大家分享大模型微调方法:LoRA,Adapter,Prefix-tuning,P-tuning,Prompt-tuning。
文末有大模型一系列文章及技术交流方式,传统美德不要忘了,喜欢本文记得收藏、关注、点赞。 文章目录 1、LoRA…
面了美团大模型算法岗(实习),这次我要上岸了。。。
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学,针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。 汇总…
用通俗易懂的方式讲解:大模型 RAG 在 LangChain 中的应用实战
Retrieval-Augmented Generation(RAG)是一种强大的技术,能够提高大型语言模型(LLM)的性能,使其能够从外部知识源中检索信息以生成更准确、具有上下文的回答。
本文将详细介绍 RAG 在 LangChain 中的应用&a…
CV计算机视觉每日开源代码Paper with code速览-2023.11.20
点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【人脸识别】FRCSyn Challenge at WACV 2024:Face Recognition Challenge in the Era of Synthetic Data 论文地址:https://arxi…
UniSA: Unified Generative Framework for Sentiment Analysis
文章目录 UniSA:统一的情感分析生成框架文章信息研究目的研究内容研究方法1.总体架构图2.基准数据集SAEval3.Task-Specific Prompt4.Modal Mask Training5.Pre-training Tasks5.1Mask Context Modeling5.2Sentiment Polarity Prediction5.3Coarse-grained Label Con…
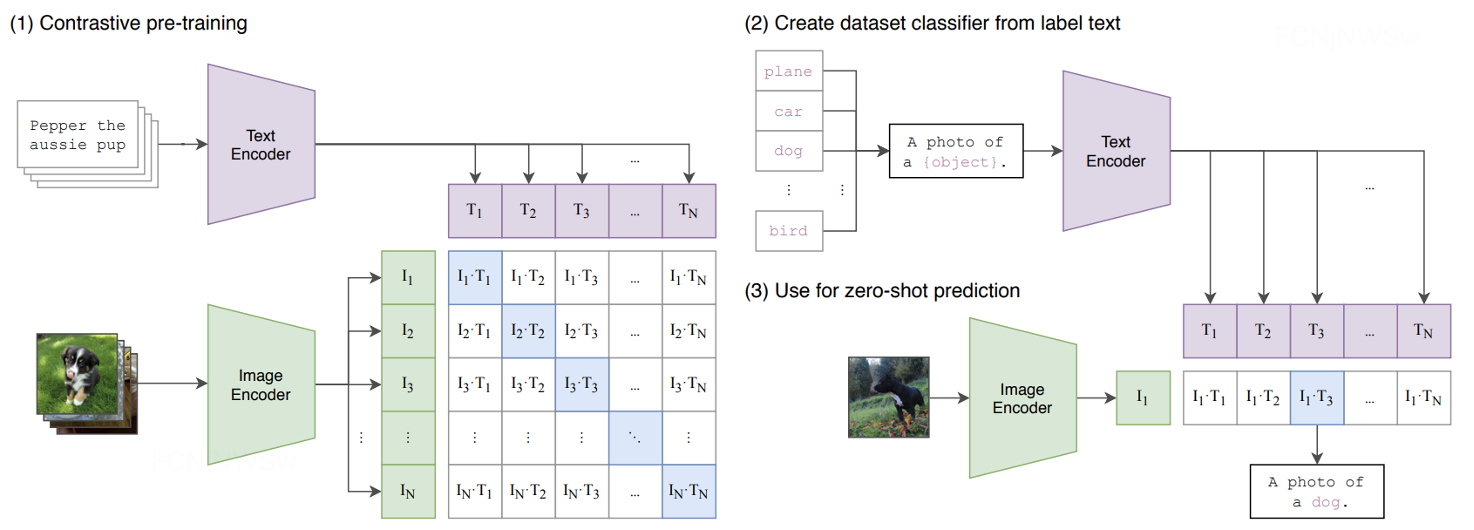
【CLIP速读篇】Contrastive Language-Image Pretraining
【CLIP速读篇】Contrastive Language-Image Pretraining 0、前言Abstract1. Introduction and Motivating Work2. Approach2.1. Natural Language Supervision2.2. Creating a Sufficiently Large Dataset2.3. Selecting an Efficient Pre-Training Method2.4. Choosing and Sc…
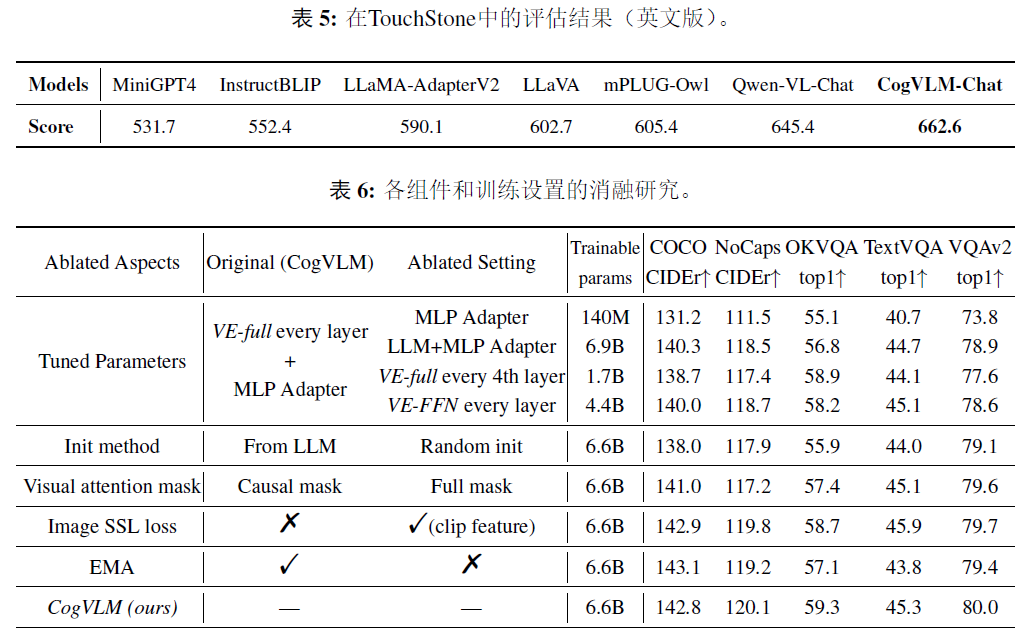
cogvlm:visual expert for large lanuage models
CogVLM: Visual Expert For Large Language Models论文笔记 - 知乎github: https://github.com/THUDM/CogVLM简介认为原先的shallow alignment效果不好(如blip-2,llava等),提出了visual expert module用于特征的deep fusion在10项…
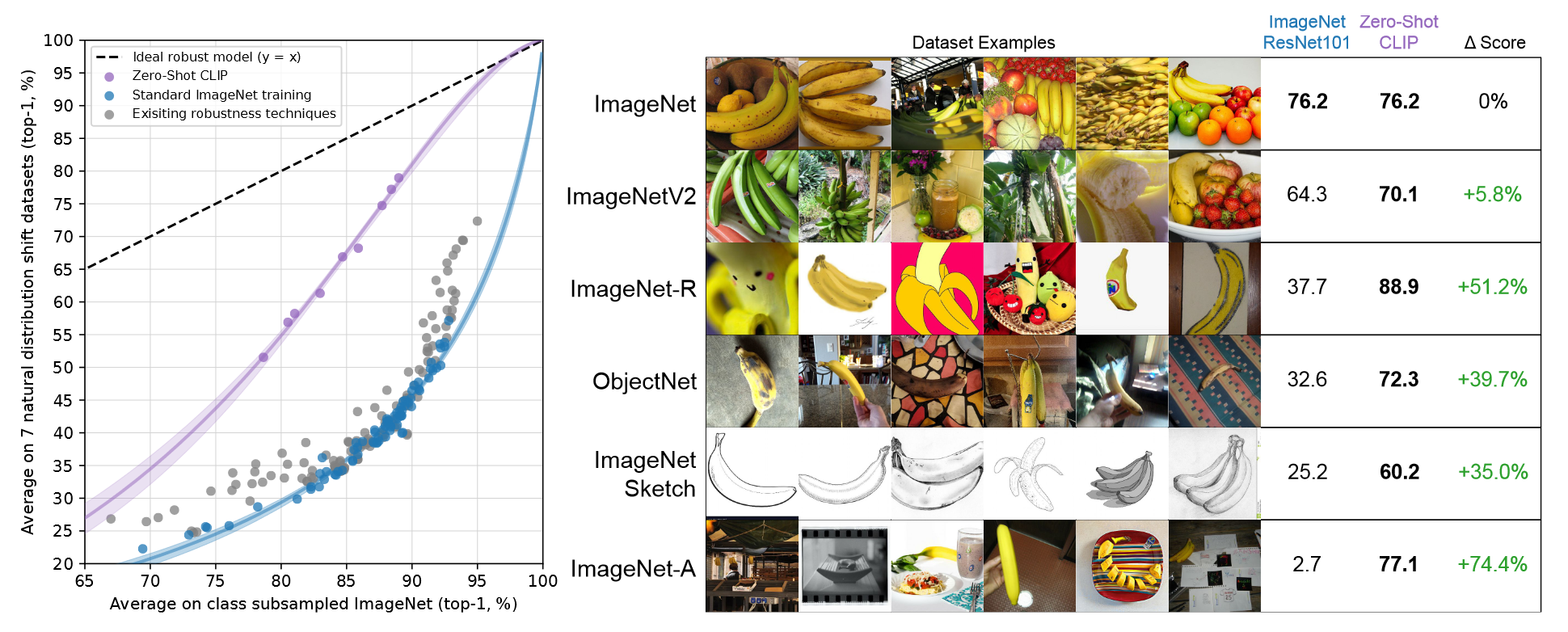
【论文精读】Learning Transferable Visual Models From Natural Language Supervision
Learning Transferable Visual Models From Natural Language Supervision 前言Abstract1. Introduction and Motivating Work2. Approach2.1. Creating a Sufficiently Large Dataset2.2. Selecting an Efficient Pre-Training Method2.3. Choosing and Scaling a Model2.4. P…
机器学习笔记 - 什么是多模态深度学习?
一、概述 人类使用五种感官来体验和解释周围的世界。我们的五种感官从五种不同的来源和五种不同的方式捕获信息。模态是指某事发生、经历或捕捉的方式。 人工智能正在寻求模仿人类大脑,终究是跳不出这具躯壳的限制。 人脑由可以同时处理多种模式的神经网络组成。想象一下进行对…

用通俗易懂的方式讲解:一文讲透最热的大模型开发框架 LangChain
在人工智能领域的不断发展中,语言模型扮演着重要的角色。特别是大型语言模型(LLM),如 ChatGPT,已经成为科技领域的热门话题,并受到广泛认可。
在这个背景下,LangChain 作为一个以 LLM 模型为核…

【LMM 012】TinyGPT-V:24G显存训练,8G显存推理的高效多模态大模型
论文标题:TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones 论文作者:Zhengqing Yuan, Zhaoxu Li, Lichao Sun 作者单位:Anhui Polytechnic University, Nanyang Technological University, Lehigh University 论文…

用通俗易懂的方式讲解大模型:使用 LangChain 封装自定义的 LLM,太棒了
Langchain 默认使用 OpenAI 的 LLM(大语言模型)来进行文本推理工作,但主要的问题就是数据的安全性,跟 OpenAI LLM 交互的数据都会上传到 OpenAI 的服务器。
企业内部如果想要使用 LangChain 来构建应用,那最好是让 La…
CV计算机视觉每日开源代码Paper with code速览-2023.10.23
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Zone Evaluation: Revealing Spatial Bias i…
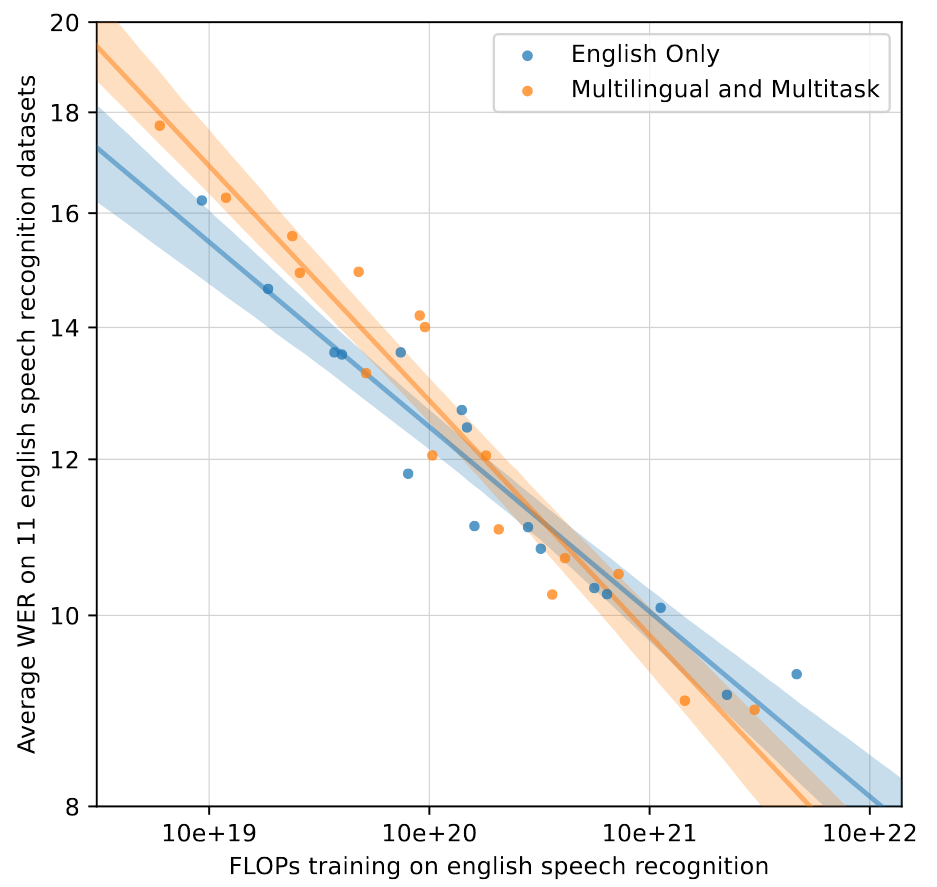
【论文精读】Robust Speech Recognition via Large-Scale Weak Supervision
Robust Speech Recognition via Large-Scale Weak Supervision 前言Abstract1. Introduction2. Approach2.1. Data Processing2.2. Model2.3. Multitask Format2.4. Training Details 3. Experiments3.1. Zero-shot Evaluation3.2. Evaluation Metrics3.3. English Speech Reco…
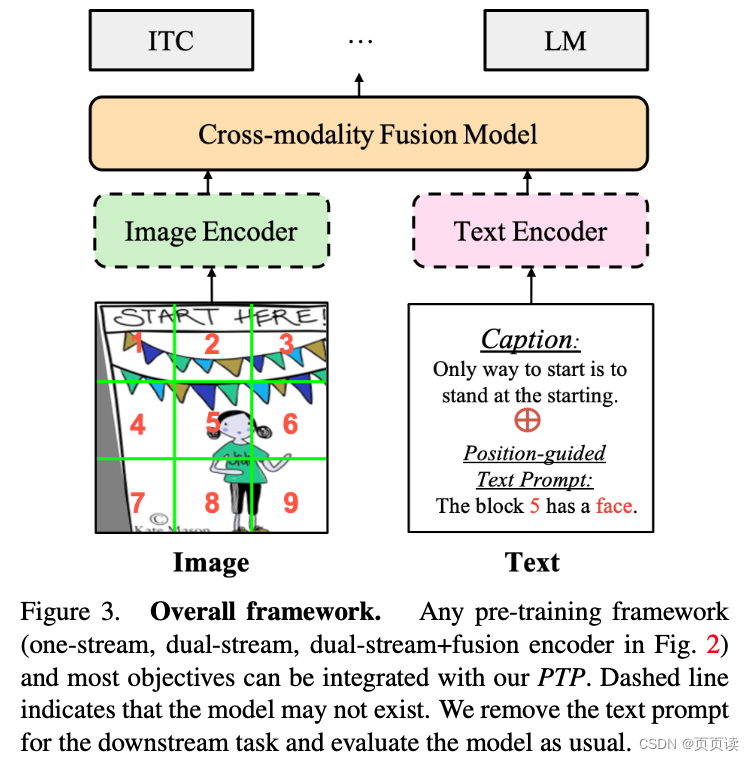
【PaperReading】3. PTP
Category Content 论文题目 Position-guided Text Prompt for Vision-Language Pre-training Code: ptp 作者 Alex Jinpeng Wang (Sea AI Lab), Pan Zhou (Sea AI Lab), Mike Zheng Shou (Show Lab, National University of Singapore), Shuicheng Yan (Sea AI Lab) 另一篇…

CV计算机视觉每日开源代码Paper with code速览-2023.11.1
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构】Battle of the Backbones: A Large-Scal…
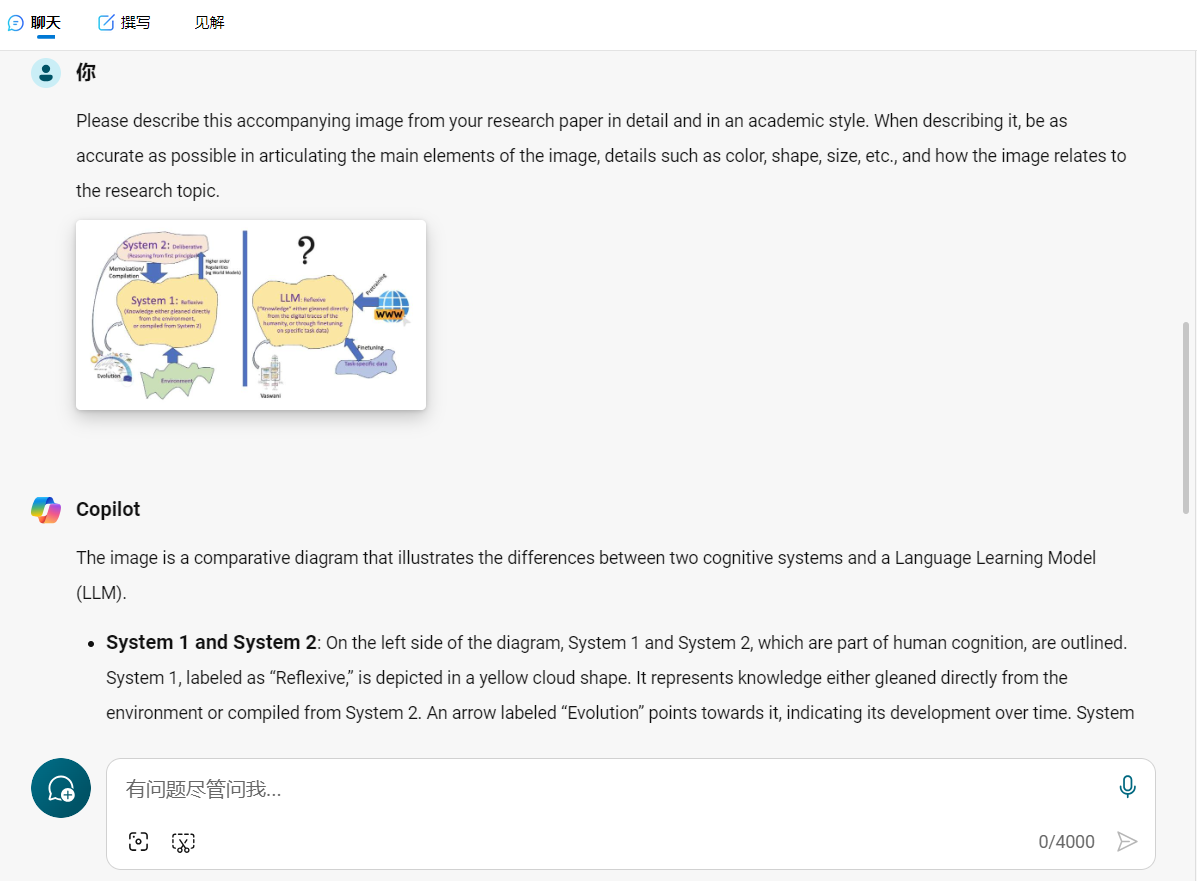
Microsoft Copilot 好像能把论文配图看明白了
🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ Microsoft Copilot 好像能把论文配图看明白了,下面是两个案例。
请用学术风格详细描述您的研究论文中的这幅配图。在描述时,请尽可能准确地阐述图片的主要元素、颜色、形状、大…
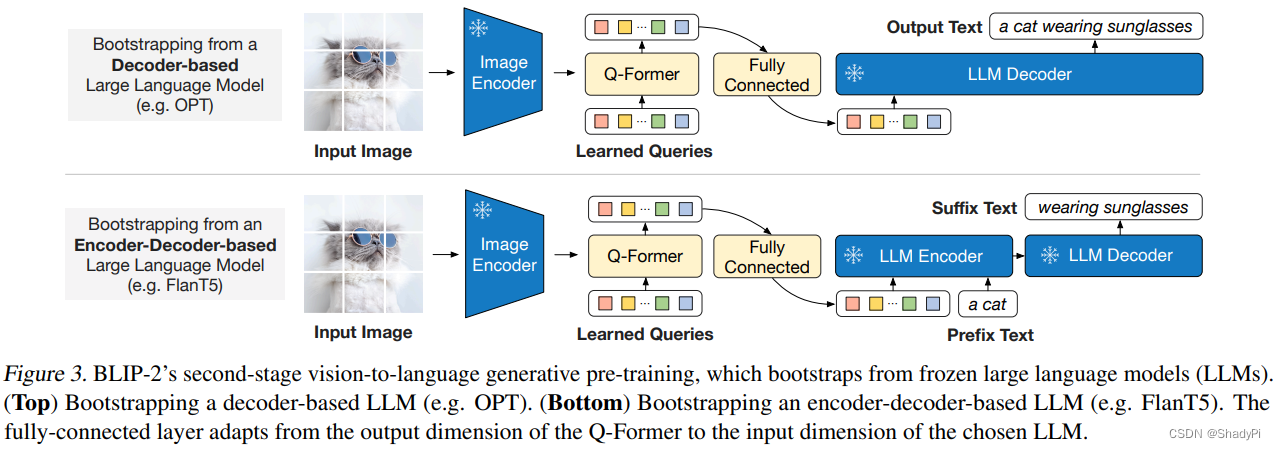
多模态小记:CLIP、BLIP与BLIP2
CLIP
使用网络上爬取得到的大量图文对进行对比学习,图文匹配的是正样本,图文不匹配的是负样本,使匹配样本的embedding之间的距离尽可能小,不匹配样本间的距离尽可能大。
缺点:网上爬的数据质量差,不能进行…
眸思MouSi:“听见世界” — 用多模态大模型点亮盲人生活
文章目录 1. Introduction1.1 APP细节展示2. Demo2.1 论文链接2.2 联系方式3. Experiment3.1 多专家的结合是否有效?3.2 如何更好的将多专家整合在一起?Reference让盲人听见世界,复旦眸思大模型打破视觉界限,用科技点亮新生活 1. Introduction
在这个世界上,视力是探索万…


因果学习篇(2)-Causal Attention for Vision-Language Tasks(文献阅读)
Causal Attention for Vision-Language Tasks
引言 这篇论文是南洋理工大学和澳大利亚莫纳什大学联合发表自2021年的CVPR顶会上的一篇文献,在当前流行的注意力机制中增加了因果推理算法,提出了一种新的注意力机制:因果注意力(CATT)ÿ…
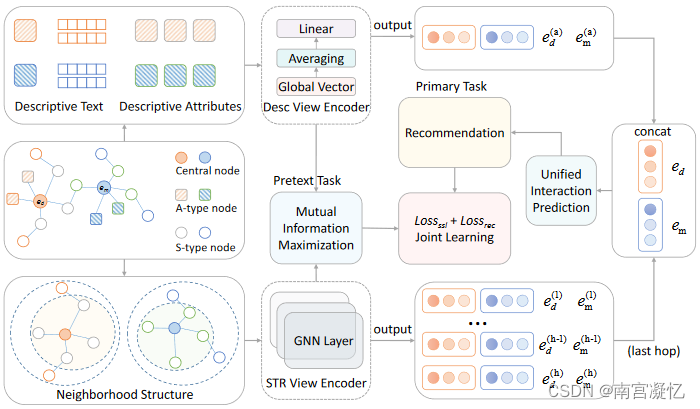
多模态推荐系统综述:一、特征交互 Bridge
一、特征交互
挑战1.如何融合不同语义空间中的模态特征并获得每种模态的偏好。GNN注意力 挑战2.如何在数据稀疏的情况下获得推荐模型的全面表示。对比学习解缠学习 挑战3. 如何优化轻量级推荐模型和参数化模态编码器。
1. Bridge
侧重于考虑多模态信息来捕获用户和项目之间的…
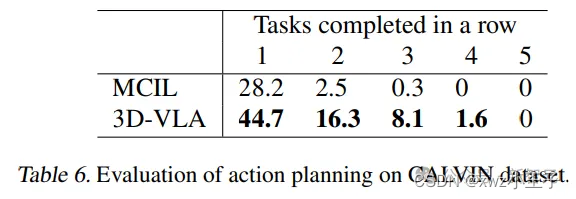
UMass、MIT等提出3D世界具身基础模型,机器人根据生成的世界模型无缝连接3D感知、推理和行动
在最近的研究中,视觉-语言-动作(VLA,vision-language-action)模型的输入基本都是2D数据,没有集成更通用的3D物理世界。
此外,现有的模型通过学习「感知到动作的直接映射」来进行动作预测,忽略了…

02.Deep Visual-Semantic Alignments for Generating Image Descriptions
目录 前言泛读摘要IntroductionRelated Work小结 精读Model3.1 学习对齐视觉与语言数据图片表征句子表征对齐目标损失函数解码文本片段对齐图像 MRNN生成描述优化 实验结论 代码 前言
本课程来自深度之眼《多模态》训练营,部分截图来自课程视频。 文章标题…
【多模态】26、视觉-文本多模态任务超详细介绍 「CLIP/LSeg/ViLD/GLIP/ALBEF/BLIP/CoCa/BEIT」
文章目录 准备知识一、CLIP:不同模态简单对比的方法更适合于图文检索1.1 CLIP 在分割上的改进工作1.1.1 LSeg1.1.2 Group ViT 1.2 CLIP 在目标检测上的改进工作1.2.1 ViLD1.2.2 GLIPv11.2.3 GLIPv2 二、ViLT/ALBEF :多模态融合在 VQA/VR 任务中更重要三、…
最详细的Ubuntu服务器搭建Stable-Diffusion教程(无显卡,仅用CPU)
1. 首先安装基本工具
# 安装python环境
sudo apt install wget git若已经安装过请忽略
2. 安装miniconda(也可以自己下载python)
下载最新的安装包
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh执行安装
./Minicon…

Talk | 西安交通大学博士生赵子祥:基于先验知识指导的多模态图像融合算法研究
本期为TechBeat人工智能社区第544期线上Talk! 北京时间11月08日(周三)20:00,西安交通大学博士生-赵子祥的Talk将准时在TechBeat人工智能社区开播! 他与大家分享的主题是: “基于先验知识指导的多模态图像融合算法研究”,介绍了他的…

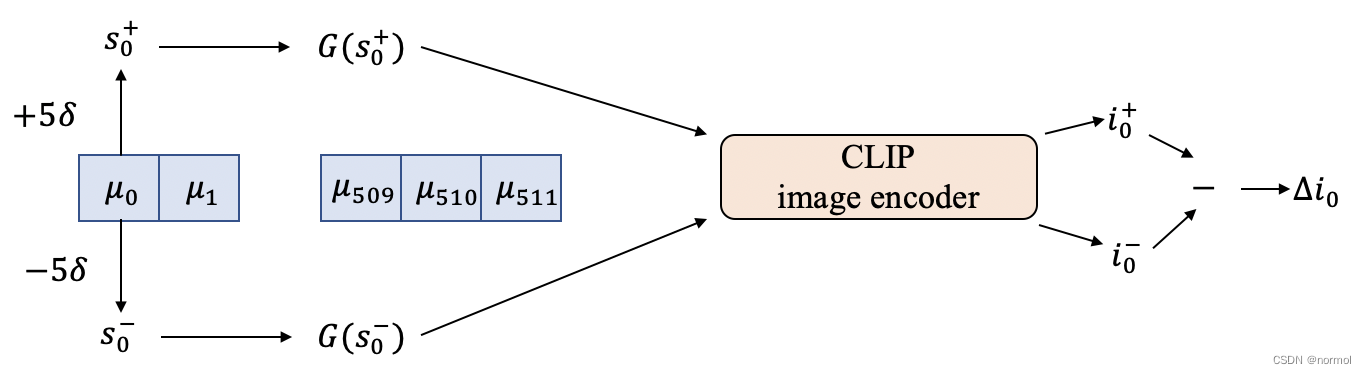
StyleCLIP global direction详解
StyleCLIP中global direction的实现原理 前言第一阶段:预计算生成latents计算均值与标准差计算 Δ i \Delta i Δi 第二阶段:计算与文本的对应关系 前言
基于的假设: CLIP中虽然图像特征与文本特征不存在一一对应的关系,但相同的语义下,图像…

多模态——旷视大模型Vary更细粒度的视觉感知实现文档级OCR或图表理解
概述
现代大型视觉语言模型(LVLMs),例如CLIP,使用一个共同的视觉词汇,以适应多样的视觉任务。然而,在处理一些需要更精细和密集视觉感知的特殊任务时,例如文档级OCR或图表理解,尤其…

LWM(LargeWorldModel)大世界模型-可文字可图片可视频-多模态LargeWorld-视频问答成功运行-实现循环问答多次问答
Large World Model(LWM)现在大火,其最主要特点是不仅能够针对文本进行检索交互,还能对图片、视频进行问答交互,自从上文《LWM(LargeWorldModel)大世界模型-可文字可图片可视频-多模态LargeWorld-详细安装记录》发出后&…

【文档智能 LLM】LayoutLLM:一种多模态文档布局模型和大模型结合的框架
前言
传统的文档理解任务,通常的做法是先经过预训练,然后微调相应的下游任务及数据集,如文档图像分类和信息提取等,通过结合图像、文本和布局结构的预训练知识来增强文档理解。LayoutLLM是一种结合了大模型和视觉文档理解技术的单…
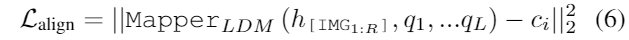
StoryGPT-V——可以生成漫画故事的多模态大模型
前言
目前,大型模型在复杂故事可视化任务方面依然面临着重大挑战。这是因为此类任务需要对框架描述中的代词(例如He、她、他们、他们)进行解析,即在分辨率和确保跨帧的角色和背景融合方面进行详细解剖。尽管存在这些挑战…

Sora后时代文生视频的探索
一、写在前面
按常理,这里应该长篇大论地介绍一下Sora发布对各行业各方面产生的影响。不过,这类文章已经很多了,我们今天主要聊聊那些已经成熟的解决方案、那些已经可以“信手拈来”的成果,并以此为基础,看看Sora发布…
多模态表征—CLIP及中文版Chinese-CLIP:理论讲解、代码微调与论文阅读
我之前一直在使用CLIP/Chinese-CLIP,但并未进行过系统的疏导。这次正好可以详细解释一下。相比于CLIP模型,Chinese-CLIP更适合我们的应用和微调,因为原始的CLIP模型只支持英文,对于我们的中文应用来说不够友好。Chinese-CLIP很好地…
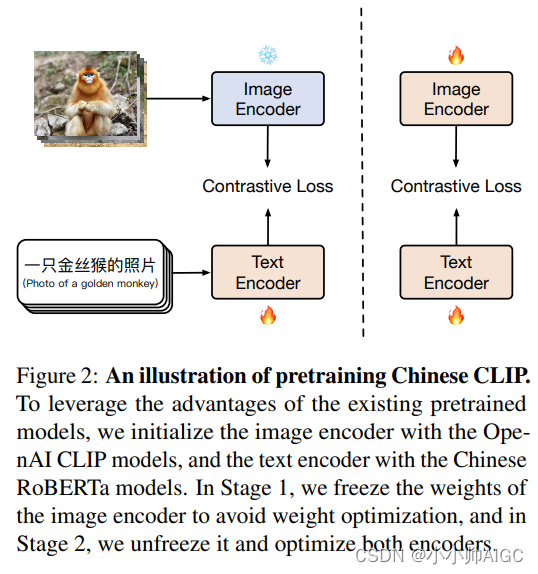
受“博比特虫”启发可实现多模态传感抓取动作的软执行器来了
软执行器可以实现对易碎和不规则形状物体的精细自适应抓取,这在生物和工程系统中至关重要。然而,目前软机器人在抓取的时候往往受制于抓取能力不足和功能限制。 博比特虫捕获猎物
最近研究人员提出了一种受博比特虫启发的多模态传感自适应软抓取器&…
2023年及以后语言、视觉和生成模型的发展和展望
一、简述 在过去的十年里,研究人员都在追求类似的愿景——帮助人们更好地了解周围的世界,并帮助人们更好地了解周围的世界。把事情做完。我们希望建造功能更强大的机器,与人们合作完成各种各样的任务。各种任务。复杂的信息搜寻任务。创造性任务,例如创作音乐、绘制新图片或…
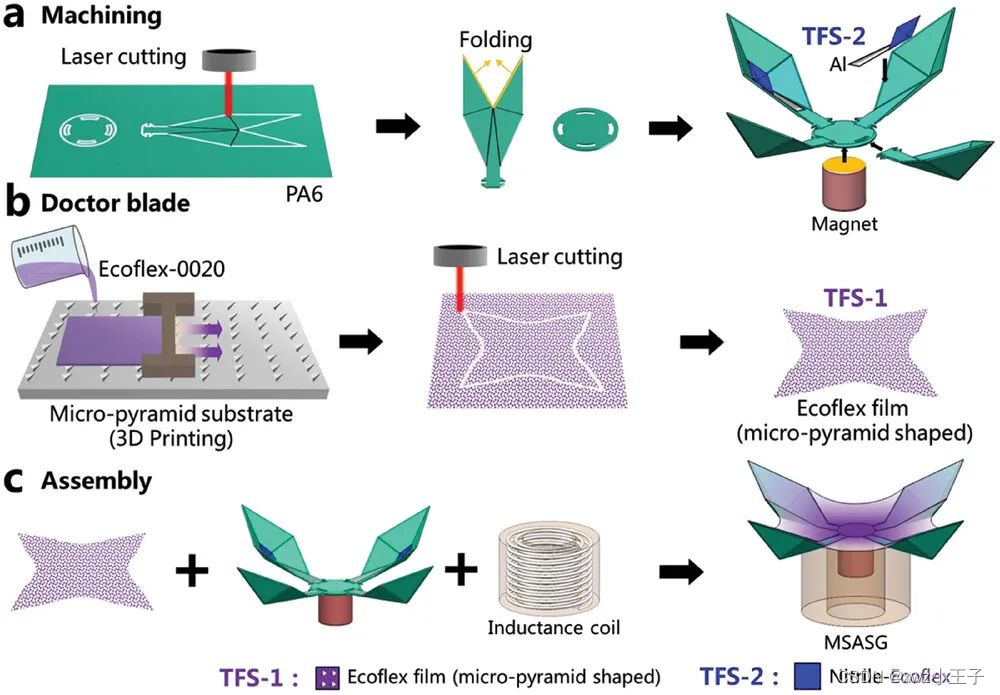
【文档智能】再谈基于Transformer架构的文档智能理解方法论和相关数据集
前言
文档的智能解析与理解成为为知识管理的关键环节。特别是在处理扫描文档时,如何有效地理解和提取表单信息,成为了一个具有挑战性的问题。扫描文档的复杂性,包括其结构的多样性、非文本元素的融合以及手写与印刷内容的混合,都…
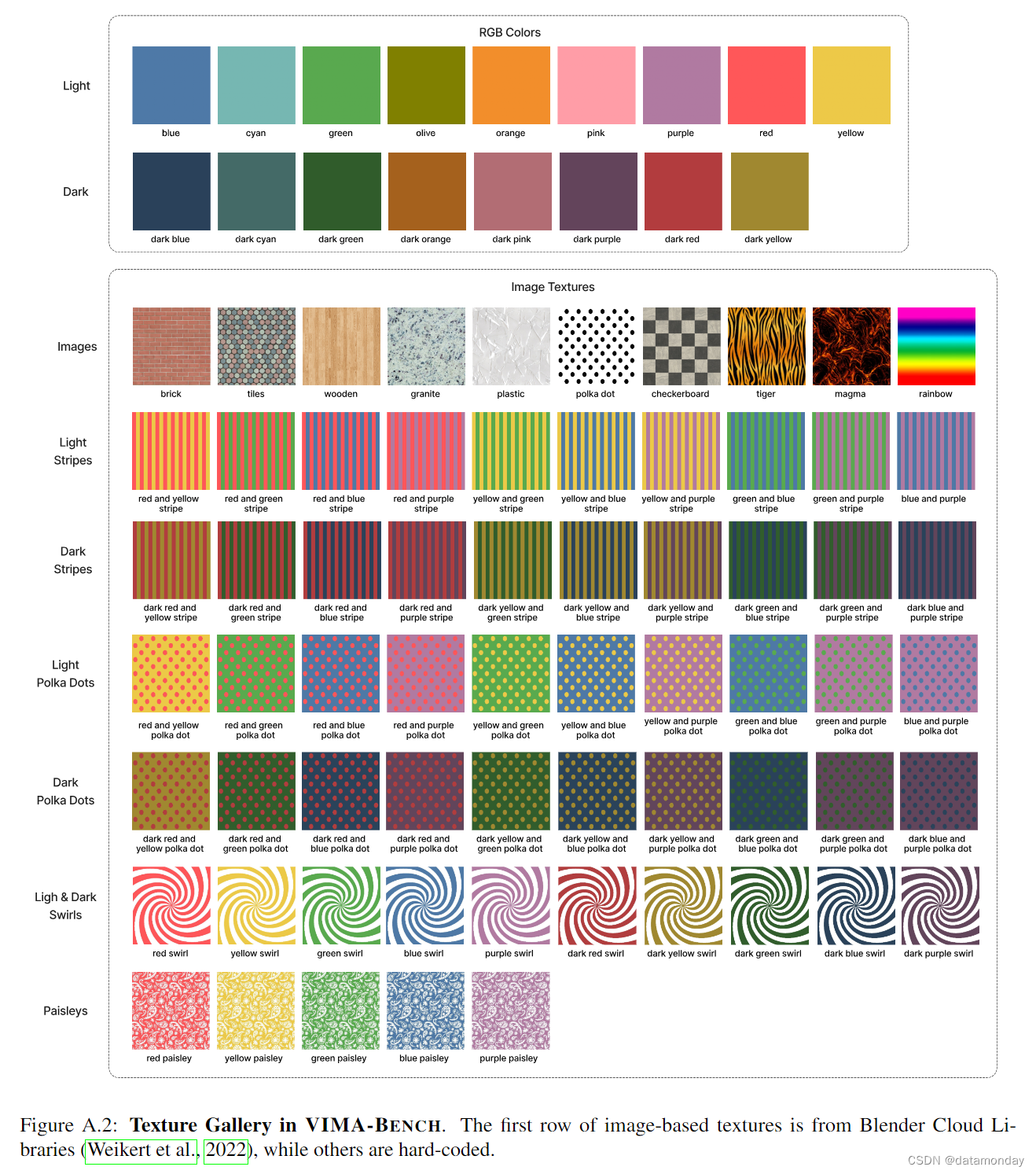
【EAI 016】VIMA: General Robot Manipulation with Multimodal Prompts
论文标题:VIMA: General Robot Manipulation with Multimodal Prompts 论文作者:Yunfan Jiang, Agrim Gupta, Zichen Zhang, Guanzhi Wang, Yongqiang Dou, Yanjun Chen, Li Fei-Fei, Anima Anandkumar, Yuke Zhu, Linxi Fan 作者单位:Stanfo…
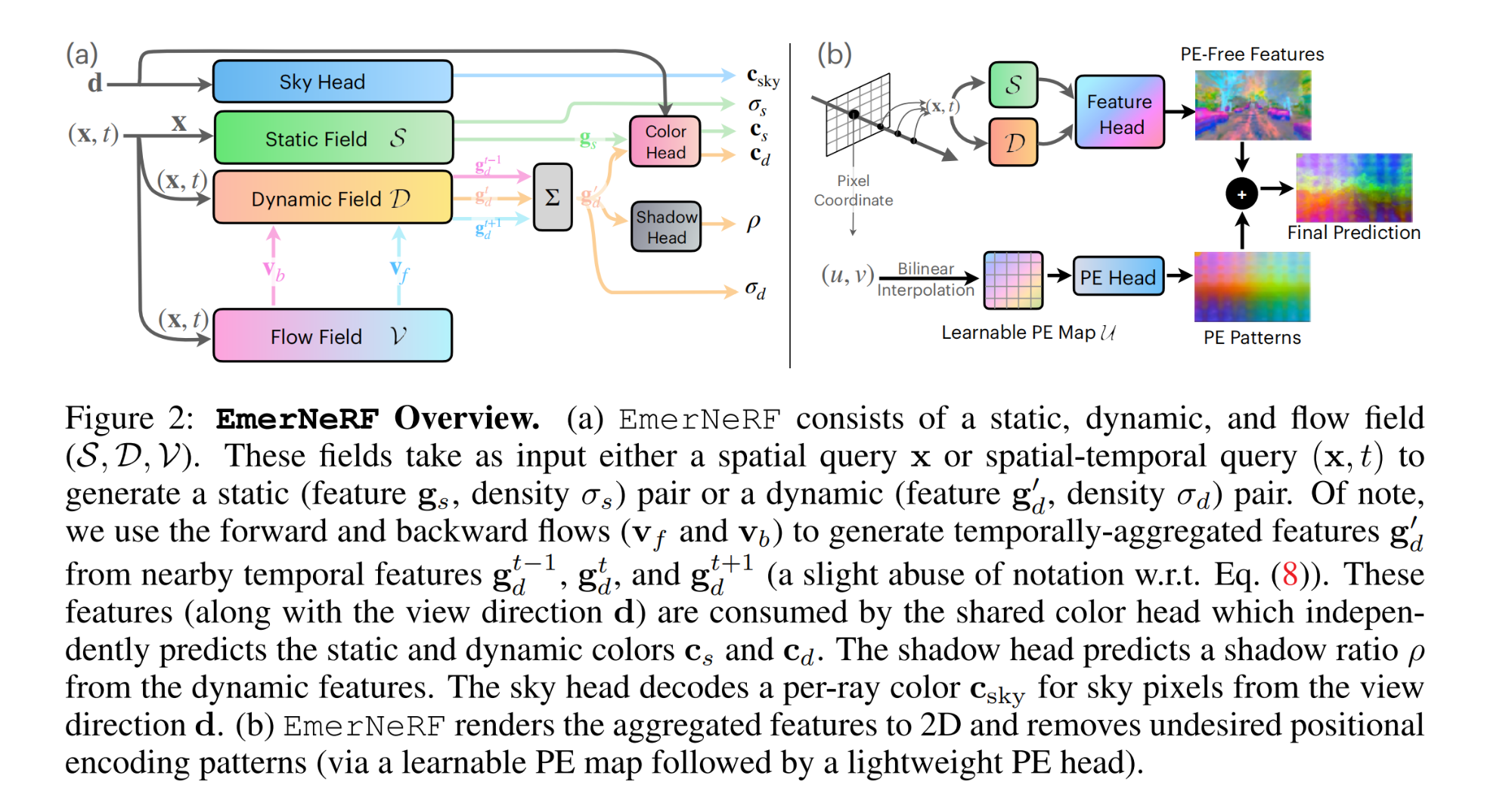
CV计算机视觉每日开源代码Paper with code速览-2023.11.6
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【点云3D目标检测】(NeurIPS2023)…

已经有多人中招,不要被AI换脸技术骗了!
您好,我是码农飞哥(wei158556),感谢您阅读本文,欢迎一键三连哦。 💪🏻 1. Python基础专栏,基础知识一网打尽,9.9元买不了吃亏,买不了上当。 Python从入门到精…

InstructPix2Pix(CVPR2023)-图像编辑论文解读
文章目录 1.摘要2.背景3.算法3.1 生成多模态训练集3.1.1生成指令及成对caption3.1.2 依据成对的caption生成成对的图像 3.2 InstructPix2Pix 4.实验结果4.1基线比较4.2消融实验 5.结论 论文:
《InstructPix2Pix: Learning to Follow Image Editing Instructions》 …
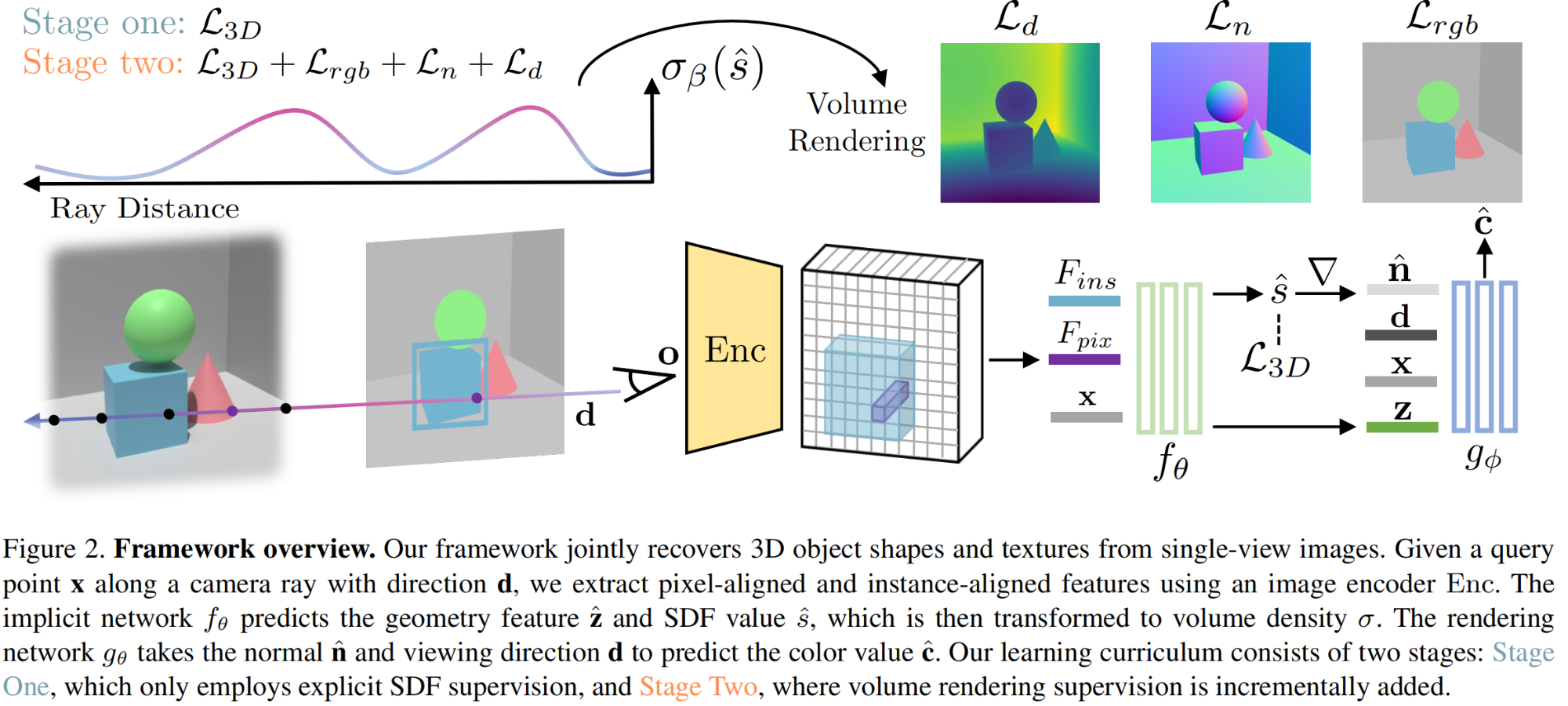
CV计算机视觉每日开源代码Paper with code速览-2023.11.2
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Re-Scoring Using Image-Language Similarit…
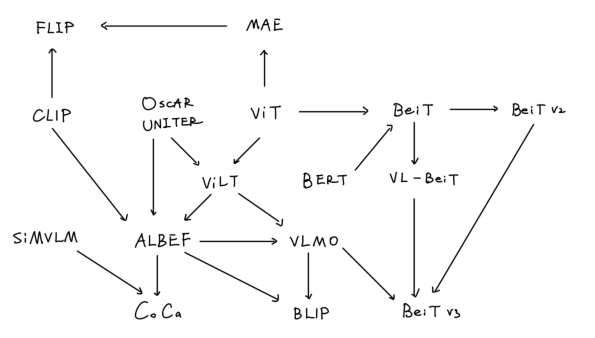
【学习笔记】多模态综述
多模态综述 前言1. CLIP & ViLT2. ALBEF3. VLMO4. BLIP5. CoCa6. BeiTv3总结参考链接 前言
本篇学习笔记虽然是多模态综述,本质上是对ViLT后多模态模型的总结,时间线为2021年至2022年,在这两年,多模态领域的模型也是卷的飞起…
深度学习神经网络学习笔记-多模态方向-13- Multimodal machine learning: A survey and taxonomy
本文为简单机翻,参考学习用 1 多模态机器学习:综述与分类 Tadas Baltruˇsaitis, Chaitanya Ahuja,和Louis-Philippe Morency 抽象——我们对世界的体验是多模态的——我们看到物体,听到声音,感觉到纹理,闻到气味&…

【多模态】25、ViLT | 轻量级多模态预训练模型(ICML2021)
文章目录 一、背景二、ViLT 方法三、效果3.1 数据集3.2 分类任务 VQA 和 NLVR23.3 Image Retrieval 论文:ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
代码:https://github.com/dandelin/vilt
出处:…

在Kaggle上使用Stable Diffusion进行AI绘图
前言
因为使用Stable Diffusion进行AI绘图需要GPU,这让其应用得到了限制本文介绍如何在Kaggle中部署Stable Diffusion,并使用免费的P100 GPU进行推理(每周可免费使用30小时),部署好后可以在任意移动端使用。本项目在s…
『大模型笔记』Sora:探索大型视觉模型的前世今生、技术内核及未来趋势
Sora:探索大型视觉模型的前世今生、技术内核及未来趋势 文章目录 一. 摘要二. 引言杨立昆推荐的关于世界模型的真正含义(或应该是什么)的好文章。原文:Sora: A Review on Background, Technology, Limitations, and Opportunities of Large Vision Models译文:Sora探索大型…

用通俗易懂的方式讲解:大模型 Rerank 模型部署及使用技巧总结
Rerank 在 RAG(Retrieval-Augmented Generation)过程中扮演了一个非常重要的角色,普通的 RAG 可能会检索到大量的文档,但这些文档可能并不是所有的都跟问题相关,而 Rerank 可以对文档进行重新排序和筛选,让…

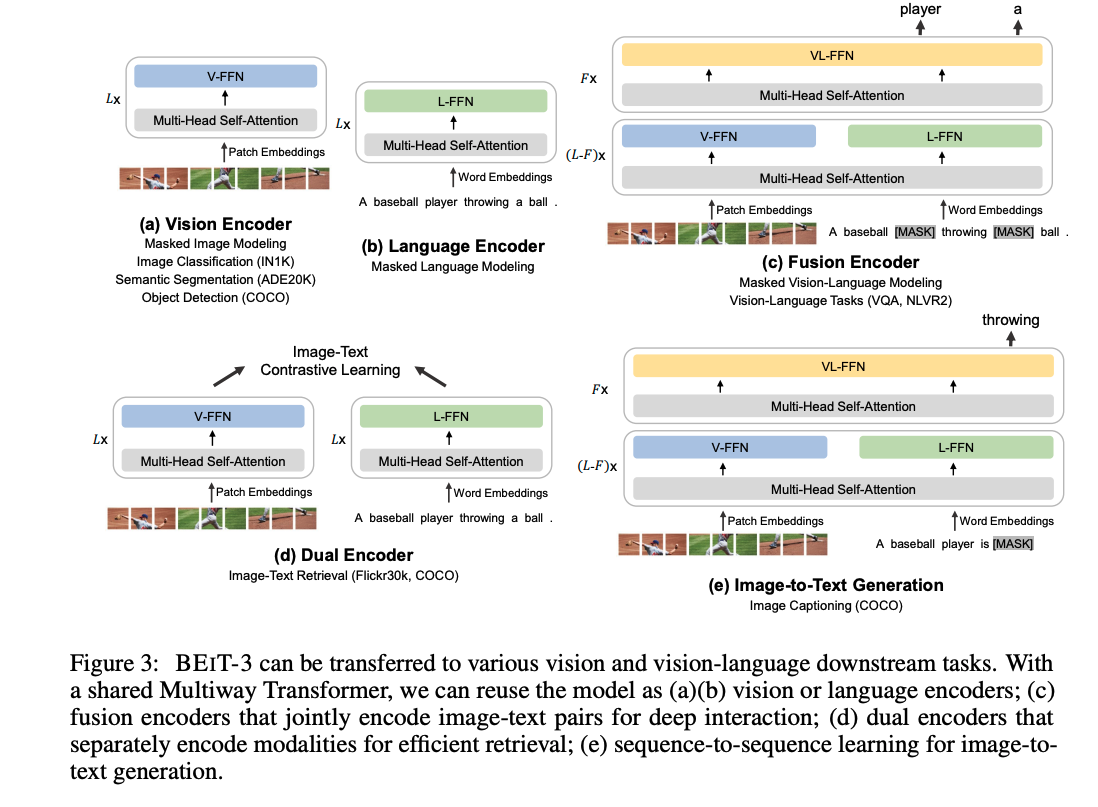
文献阅读:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks
文献阅读:Image as a Foreign Language: BEIT Pretraining for All Vision and Vision-Language Tasks 1. 内容简介2. 模型结构 1. 数据处理2. 模型结构设计3. 模型训练 3. 实验结果 1. 图文联合任务 1. Visual Question Answering (VQA)2. Visual Reasoning3. Imag…

TEASEL: A transformer-based speech-prefixed language model
文章目录 TEASEL:一种基于Transformer的语音前缀语言模型文章信息研究目的研究内容研究方法1.总体框图2.BERT-style Language Models(基准模型)3.Speech Module3.1Speech Temporal Encoder3.2Lightweight Attentive Aggregation (LAA) 4.训练…
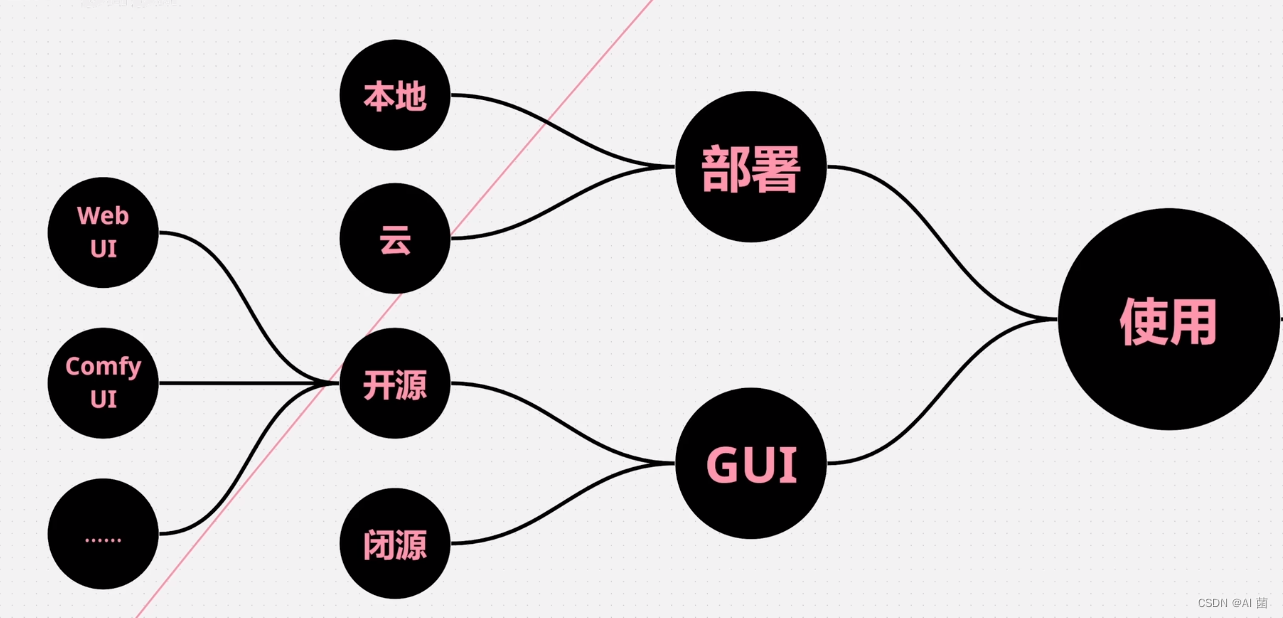
最强文生图跨模态大模型:Stable Diffusion
文章目录 一、概述二、Stable Diffusion v1 & v22.1 简介2.2 LAION-5B数据集2.3 CLIP条件控制模型2.4 模型训练 三、Stable Diffusion 发展3.1 图形界面3.1.1 Web UI3.1.2 Comfy UI 3.2 微调方法3.1 Lora 3.3 控制模型3.3.1 ControlNet 四、其他文生图模型4.1 DALL-E24.2 I…

【人工智能 | 多模态】几种常见的多模态任务
一、什么是多模态
多模态(multimodal)是指涉及到多种模态(如视觉、语音、文本等)的数据或信息。在计算机科学和人工智能领域中,多模态通常指将多种类型的数据或信息相结合,来解决特定的问题或任务。
以图…
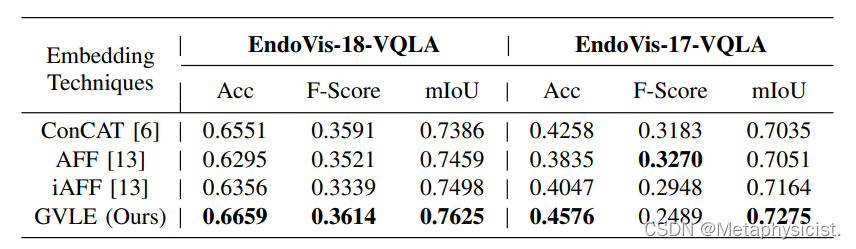
文献学习-22-Surgical-VQLA:具有门控视觉语言嵌入的转换器,用于机器人手术中的视觉问题本地化回答
Authors: Long Bai1† , Mobarakol Islam2† , Lalithkumar Seenivasan3 and Hongliang Ren1,3,4∗ , Senior Member, IEEE
Source: 2023 IEEE International Conference on Robotics and Automation (ICRA 2023) May 29 - June 2, 2023. London, UK Abstract:
尽管有计算机辅…

论文笔记 EMNLP 2021|Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for
文章目录1 简介1.1 动机1.2 创新2 方法2.1 模态编码2.2 模态中互信息最大化2.3 融合中互信息最大化3 实验1 简介
论文题目:Improving Multimodal Fusion with Hierarchical Mutual Information Maximization for Multimodal Sentiment Analysis 论文来源࿱…

首个大规模图文多模态数据集LAION-400M介绍
前言
openAI的图文多模态模型CLIP证明了图文多模态在多个领域都具有着巨大潜力,随之而来掀起了一股图文对比学习的风潮。
就在前几天(2022年12月),连Kaiming都入手这一领域,将MAE的思路与CLIP的思路结合,…
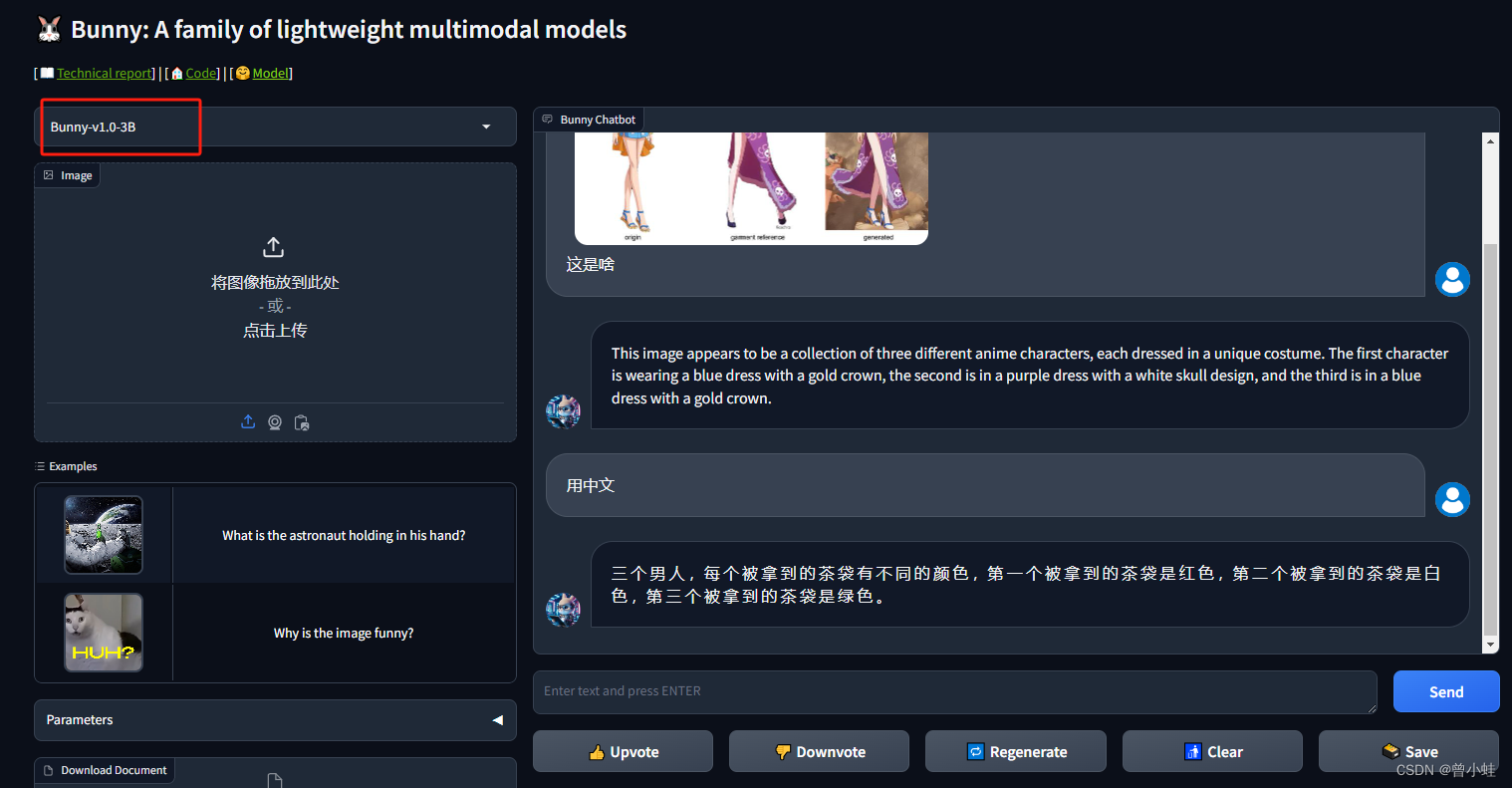
【MLLM+轻量多模态模型】24.02.Bunny-v1.0-2B-zh: 轻量级多模态语言模型 (效果一般)
24.02 北京人工智能研究院(BAAI)提出以数据为中心的轻量级多模态模型
arxiv论文:2402.Efficient Multimodal Learning from Data-centric Perspective 代码:https://github.com/BAAI-DCAI/Bunny 在线运行:https://wis…
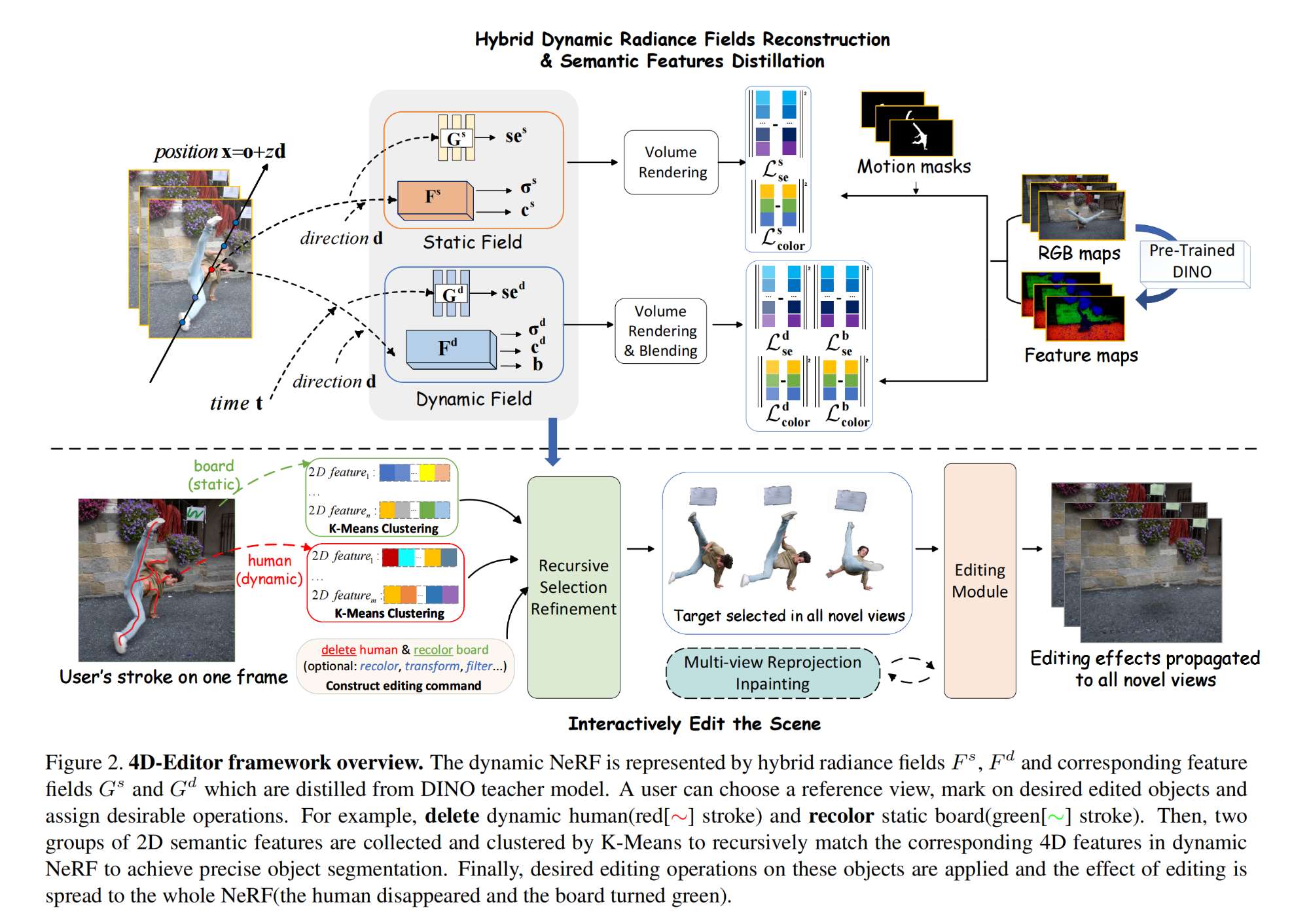
CV计算机视觉每日开源代码Paper with code速览-2023.10.27
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】(Ne…
AI推介-多模态视觉语言模型VLMs论文速览(arXiv方向):2024.02.25-2024.03.01
论文目录~ 1.Panda-70M: Captioning 70M Videos with Multiple Cross-Modality Teachers2.Generalizable Whole Slide Image Classification with Fine-Grained Visual-Semantic Interaction3.Enhancing Visual Document Understanding with Contrastive Learning in Large Vis…
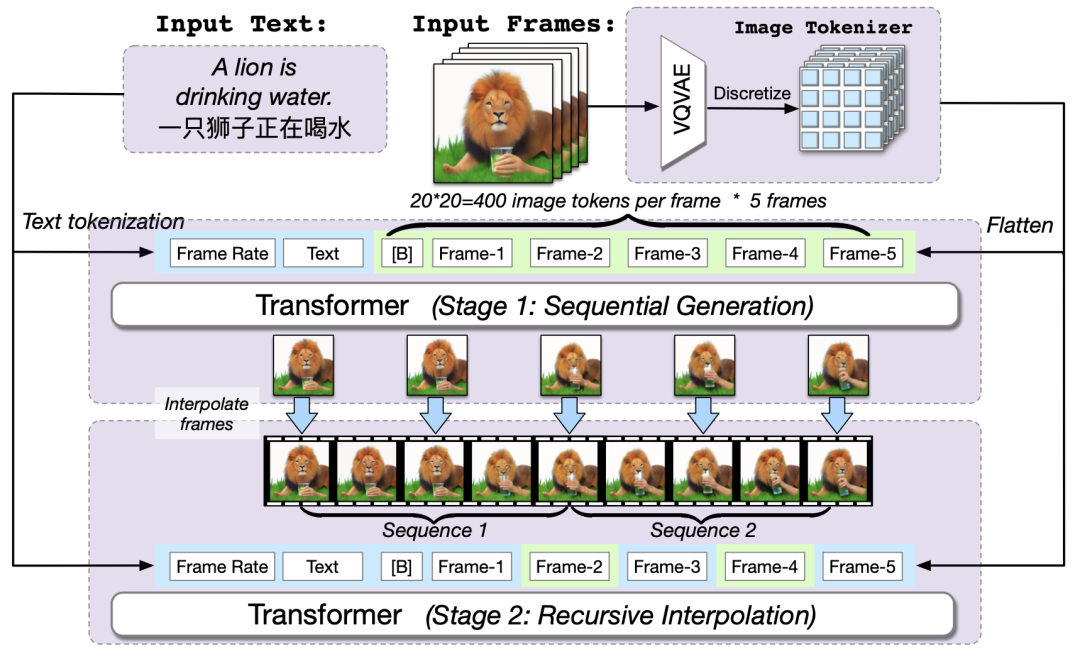
【LLM多模态】Cogview3、DALL-E3、CogVLM、CogVideo模型
note 文章目录 noteVisualGLM-6B模型图生文:CogVLM-17B模型1. 模型架构2. 模型效果 文生图:CogView3模型DALL-E3模型CogVideo模型网易伏羲-丹青模型Reference VisualGLM-6B模型
VisualGLM 是一个依赖于具体语言模型的多模态模型,而CogVLM则是…
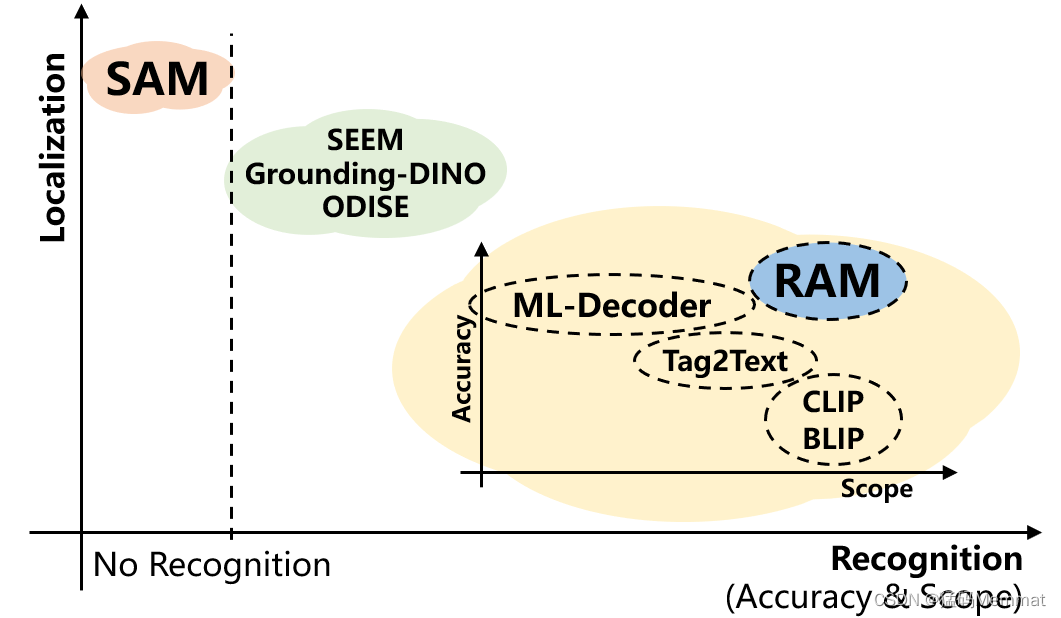
万物识别RAM:图像识别模型,Zero-Shot超越有监督
文章目录 RAM的优势RAM的创新点总结与展望参考文献大语言模型(Large Language Models)已经给自然语言处理(NLP)领域带来了新的革命。在计算机视觉(CV)领域,Facebook近期推出的Segment Anything Model(SAM)工作,在视觉定位(Localization)任务上取得了令人振奋的结果…

使用多模态数据映射大脑网络
前言
人脑由解剖和功能性的网络组织而成,这些网络涉及大规模分布但相互作用的脑区。不同脑区之间的同步性已在手指敲击或视觉刺激等实验任务活动中观察到,但更重要的是,也在无任务条件下(即静息态)测量的内源性活动中被观察到。即使在休息时…

Grounding DINO:根据文字提示检测任意目标
文章目录 1. 背景介绍2. 方法创新2.1 Feature Extraction and Enhancer2.2 Language-Guided Query Selection2.3 Cross-Modality Decoder2.4 Sub-Sentence Level Text Feature2.5 Loss Function3. 实验结果3.1 Zero-Shot Transfer of Grounding DINO3.2 Referring Object Detec…

NLP实践——VQA/Caption生成模型BLIP-2的应用介绍
NLP实践——VQA/Caption生成模型BLIP-2的应用介绍1. 简介2. 模型下载3. 运行环境4. 模型应用1. 简介
今天介绍一个跨模态模型,也是最近比较火的一个工作,叫做BLIP-2。很久很久之前我写过一个简单的image caption项目的介绍,那个模型原理比较…
CV计算机视觉每日开源代码Paper with code速览-2023.11.7
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构】Understanding Deep Representation Lea…
李沐论文精读系列四:CLIP和改进工作串讲(LSeg、GroupViT、VLiD、 GLIPv1、 GLIPv2、CLIPasso)
文章目录一、CLIP1.1 简介1.1.1 前言1.1.2 模型结构1.1.3 模型效果1.1.3.1 对自然分布偏移的鲁棒性1.1.3.2 StyleCLIP1.1.3.3 CLIPDraw1.1.3.4 zero-shot检测1.1.3.5 CLIP视频检索1.1.4 导言1.2 方法1.2.1 自然语言监督的优势1.2.2 预训练方法(训练效率至关重要&…
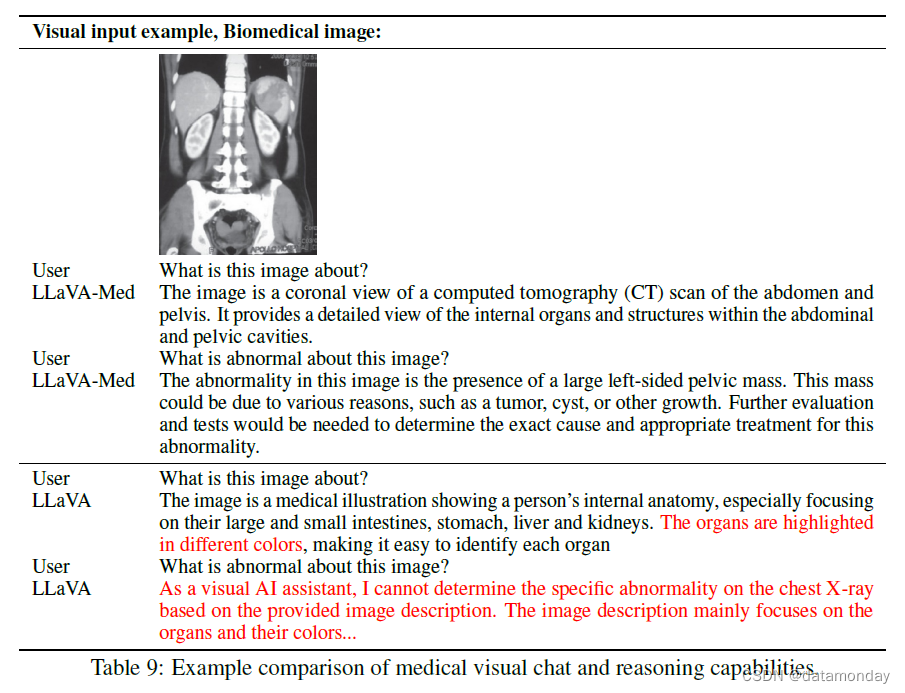
【LMM 003】生物医学领域的垂直类大型多模态模型 LLaVA-Med
论文标题:LLaVA-Med: Training a Large Language-and-Vision Assistant for Biomedicine in One Day 论文作者:Chunyuan Li∗, Cliff Wong∗, Sheng Zhang∗, Naoto Usuyama, Haotian Liu, Jianwei Yang Tristan Naumann, Hoifung Poon, Jianfeng Gao 作…
大模型学习之书生·浦语大模型2——趣味Demo
文章目录 Demo效果目录大模型及InternLM模型介绍InterLM-Chat-7B智能对话DemoLagent智能体工具调用Demo浦语灵笔图文创作理解Demo通用环境配置实践智能对话Demo1 创建开发机2 进入开发机并创建环境及安装依赖3 模型下载4 代码准备5 终端运行6 web demo运行 Lagent智能体工具调用…

PVIT:利用位置信息增强多模态模型理解用户意图的能力
论文链接: https://arxiv.org/abs/2308.13437 代码链接: https://github.com/PVIT-official/PVIT Demo: https://huggingface.co/spaces/PVIT/pvit 引言
随着ChatGPT等语言大模型的走红,越来越多人尝试探索为语言大模型赋予视觉能…
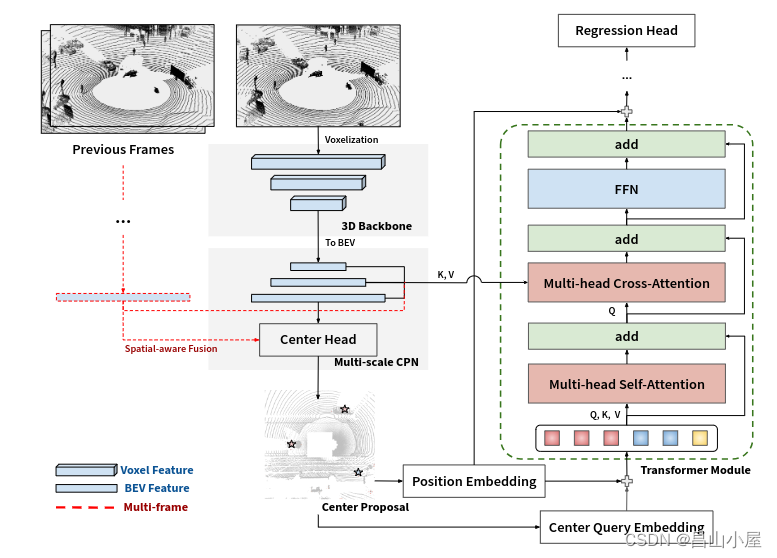
【多模态融合】TransFusion学习笔记(1)
工作上主要还是以纯lidar的算法开发,部署以及系统架构设计为主。对于多模态融合(这里主要是只指Lidar和Camer的融合)这方面研究甚少。最近借助和朋友们讨论论文的契机接触了一下这方面的知识,起步是晚了一点,但好歹是开了个头。下面就借助TransFusion论文…
lavis多模态开源框架学习--安装
安装lavis安装lavis测试安装问题过程中的其他操作安装lavis
因为lavis已经发布在pypi中,所以可以直接利用pip安装
pip install salesforce-lavis测试安装
from lavis.models import model_zoo
print(model_zoo)
#
# Architectures Types
#
# …
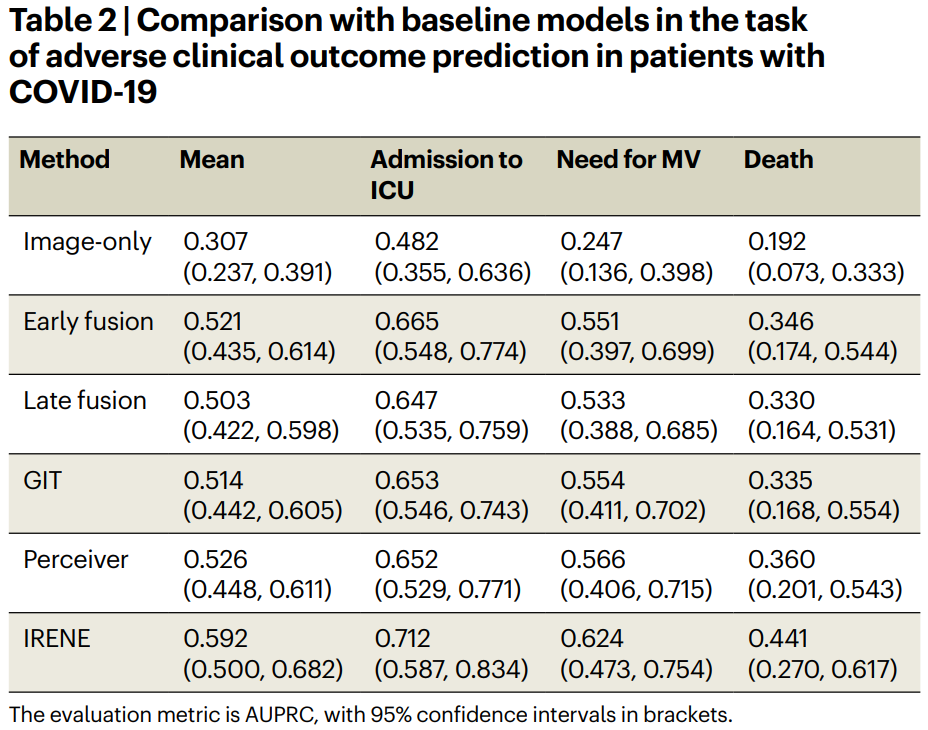
基于肺部图片与文本信息的多模态模型架构
文章题为 「A transformer-based representation learning model with unified processing of multimodal input for clinical diagnostics」 https://www.nature.com/articles/s41551-023-01045-x (arXiv版链接: https://arxiv.org/abs/2306.00864) htt…
CV计算机视觉每日开源代码Paper with code速览-2023.10.30
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【语义分割】(NeurIPS2023)SmooSe…
CV计算机视觉每日开源代码Paper with code速览-2023.10.20
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】Click on Mask: A Labor-efficient Annotati…

【必知必懂论文】之多模态实体识别
引言
命名实体识别(NER)是自然语言处理(NLP)领域中的最基础、最核心的任务之一,该任务旨在识别出文本中的命名实体(通常指特定类型事物的名称或符号,一般是一个名词或者短语),并将识别出的实体…
CV计算机视觉每日开源代码Paper with code速览-2023.10.31
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构】(NeurIPS2023)Fa…

《IEEE Transactions on Robotics》发表!北京大学研究团队推出具有多种运动模态的软体两栖机器人
两栖机器人以其在复杂水陆混合环境中的卓越适应性而脱颖而出,成为非结构化场景下信息监测、资源勘探和灾难救援等多元化任务的理想选择。凭借能够在水生和陆生环境中自如切换的优势,两栖机器人在如上任务执行过程中展现出对多变环境的惊人适应能力。
在…
以桨为楫 修己度人(四)
目录 1.人工智能开创的新时代 2.使命开启飞桨一春独占 3.技术突破奠定飞桨品牌一骑绝尘 4.行业应用积淀飞桨品牌一枝独秀 5.生态传播造就飞桨品牌一众独妍 6.深度学习平台的现状和未来思考
深度学习平台的现状和未来思考 作为我国首个功能丰富、开源开放的深度学习中文平台&am…
深度学习神经网络学习笔记-多模态方向-12-DBpedia: A Nucleus for a Web of Open Data
摘要
DBpedia是一个社区努力从维基百科中提取结构化信息,并使这些信息在网络上可用。DBpedia允许您对来自维基百科的数据集提出复杂的查询,并将网络上的其他数据集链接到维基百科数据。我们描述了DBpedia数据集的提取,以及产生的信息如何在网…

基于LLMs的多模态大模型(MiniGPT-4,LLaVA,mPLUG-Owl,InstuctBLIP,X-LLM)
这个系列的前一些文章有:
基于LLMs的多模态大模型(Visual ChatGPT,PICa,MM-REACT,MAGIC)基于LLMs的多模态大模型(Flamingo, BLIP-2,KOSMOS-1,ScienceQA)
前…
CV计算机视觉每日开源代码Paper with code速览-2023.12.1
点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】TransNeXt: Robust Foveal Visual Perception for Vision Transformers 论文地址:http…

多模态论文阅读-LLaVA
Visual Instruction Tuning Abstract1. Introduction2. Related Work3. GPT-assisted Visual Instruction Data Generation4. Visual Instruction Tuning4.1 Architecture4.2 Training 5 Experiments5.1 Multimodal Chatchot5.2 ScienceQA 6 Conclusion Abstract
使用机器生成…

一文了解多模态数字人
一、什么是多模态数字人
多模态数字人是一种通过多种传感器获取人体数据,使用计算机技术进行处理和分析,构建出具有多种感知和交互能力的虚拟人。多模态数字人可以通过视觉、听觉、触觉等多种感知方式与人类进行交互,具有高度的仿真度和个性…
清华系2B模型杀出支持离线本地化部署,可以个人电脑或者手机上部署的多模态大模型,超越 Mistral-7B、LLaMA-13B
清华系2B模型杀出支持离线本地化部署,可以个人电脑或者手机上部署的多模态大模型,超越 Mistral-7B、LLaMA-13B。 2 月 1 日,面壁智能与清华大学自然语言处理实验室共同开源了系列端侧语言大模型 MiniCPM,主体语言模型 MiniCPM-2B …
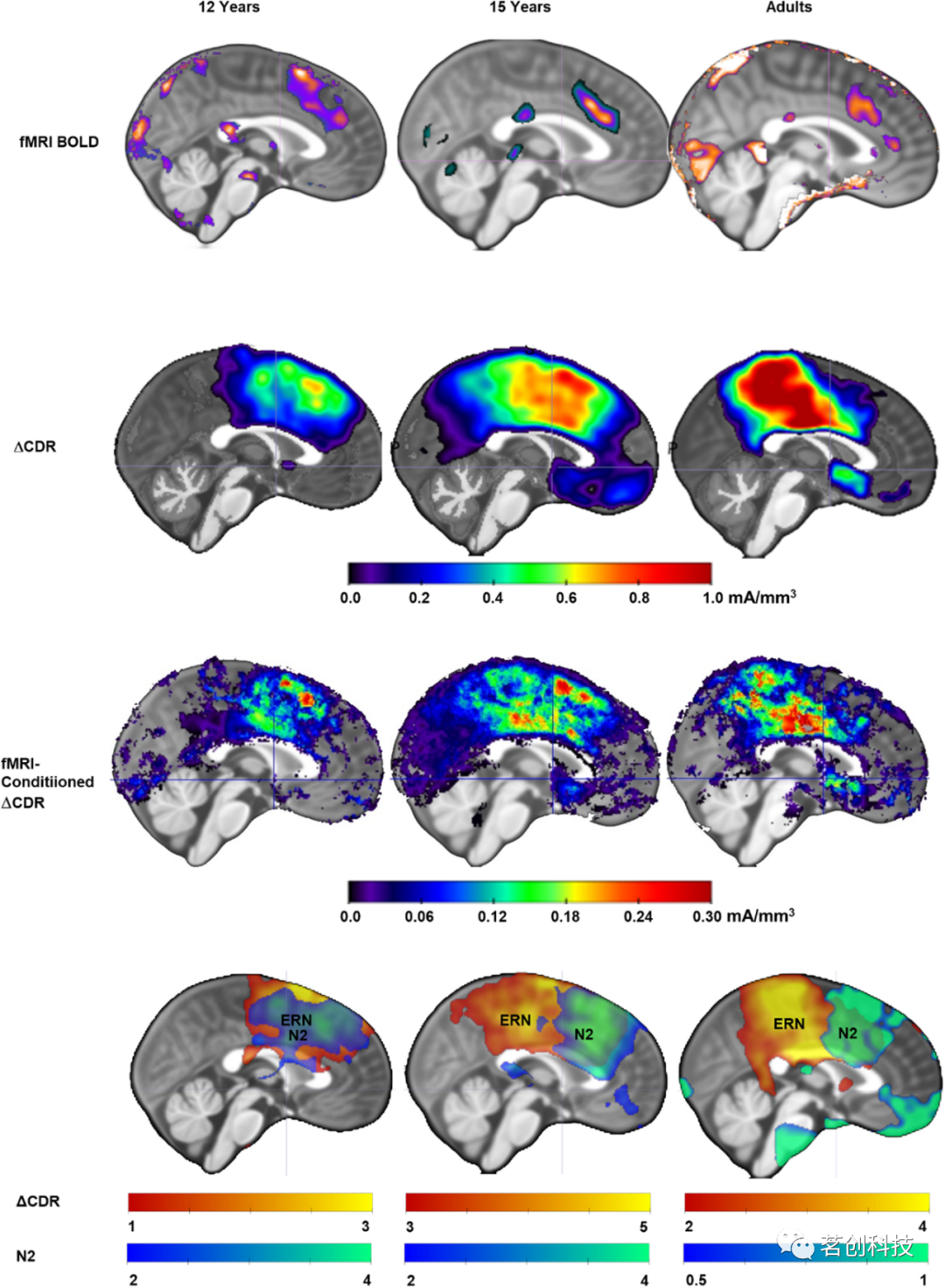
青少年和成人错误监测神经源的多模态研究
导读
儿童和成人对目标导向行为的监控能力不同,这可以通过几种任务和技术来测量。此外,最近的研究表明,错误监测的个体差异在调节焦虑情绪的倾向方面具有重要作用,而且这种调节作用会随着年龄的增长而变化。本研究使用多模态方法…

【文档智能】:GeoLayoutLM:一种用于视觉信息提取(VIE)的预训练模型
前言
文章介绍了一种用于视觉信息提取(VIE)的预训练模型:GeoLayoutLM。GeoLayoutLM通过显式建模几何关系和特殊的预训练任务来提高文本和布局的特征表示。该模型能够提高文档信息抽取的性能。
一、提出背景
当前多模态预训练模型在 SER 任…
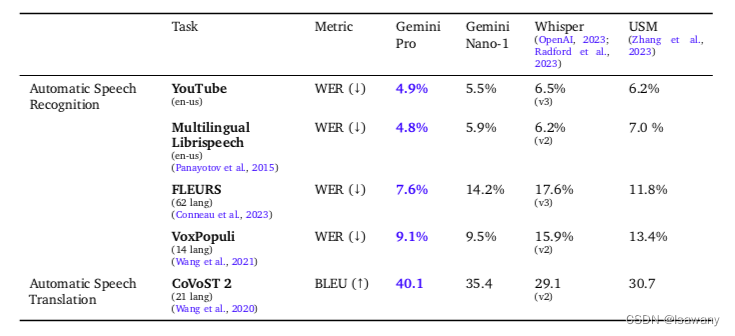
论文笔记--Gemini: A Family of Highly Capable Multimodal Models
论文笔记-- 1. 文章简介2. 文章概括3 文章重点技术3.1 模型架构3.2 训练数据3.3 模型评估3.3.1 文本3.3.1.1 Science3.3.1.2 Model sizes3.3.1.3 Multilingual3.3.1.4 Long Context3.3.1.5 Human preference 3.3.2 多模态3.3.2.1 图像理解3.3.2.2 视频理解3.3.2.3 图像生成3.3.…

【多模态】27、Vary | 通过扩充图像词汇来提升多模态模型在细粒度感知任务(OCR等)上的效果
文章目录 一、背景二、方法2.1 生成 new vision vocabulary2.1.1 new vocabulary network2.1.2 Data engine in the generating phrase2.1.3 输入的格式 2.2 扩大 vision vocabulary2.2.1 Vary-base 的结构2.2.2 Data engine2.2.3 对话格式 三、效果3.1 数据集3.2 图像细粒度感…
CV计算机视觉每日开源代码Paper with code速览-2023.10.12
精华置顶 墙裂推荐!小白如何1个月系统学习CV核心知识:链接 点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【目标检测】A Novel Voronoi-based Convolutional Neura…
CLIP(Contrastive Language-Image Pretraining)
概念
是一个由 OpenAI 开发的深度学习模型,它融合了文本和图像的信息,以便同时理解和生成文本和图像。CLIP 可以执行各种任务,包括图像分类、文本描述生成、图像生成以文本描述等。
多模态 CLIP 的核心思想是使用对比学习来训练一个模型&am…
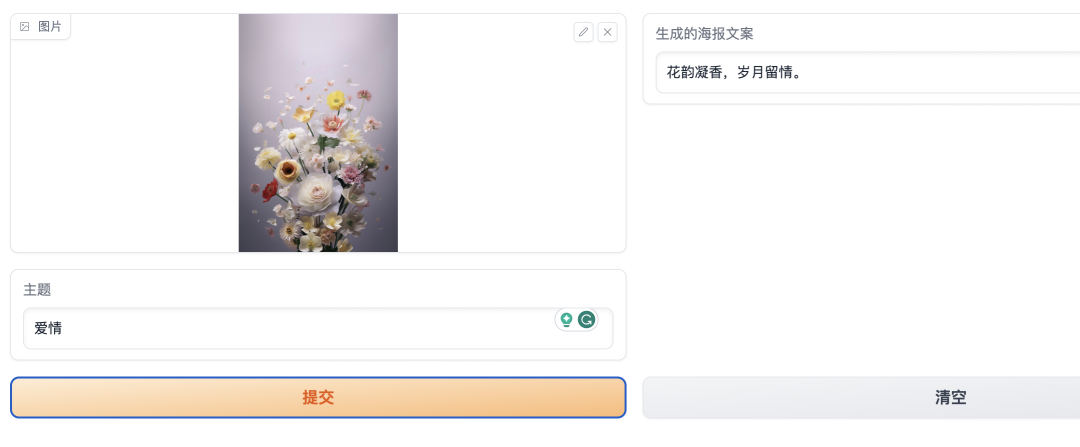
用通俗易懂的方式讲解大模型:使用 LangChain 和大模型生成海报文案
最近看到某平台在推 LangChain 的课程,其中有个示例是让 LangChain 来生成图片的营销文案,我觉得这个示例挺有意思的,于是就想自己实现一下,顺便加深一下 LangChain 的学习。 今天就介绍一下如何使用 LangChain 来实现这个功能&am…
【LMM 002】大型语言和视觉助手 LLaVA-1.5
论文标题:Improved Baselines with Visual Instruction Tuning 论文作者:Haotian Liu, Chunyuan Li, Yuheng Li, Yong Jae Lee 作者单位:University of Wisconsin-Madison, Microsoft Research, Columbia University 论文原文:htt…
CV计算机视觉每日开源代码Paper with code速览-2023.11.14
点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】Aggregate, Decompose, and Fine-Tune: A Simple Yet Effective Factor-Tuning Method for Vision…
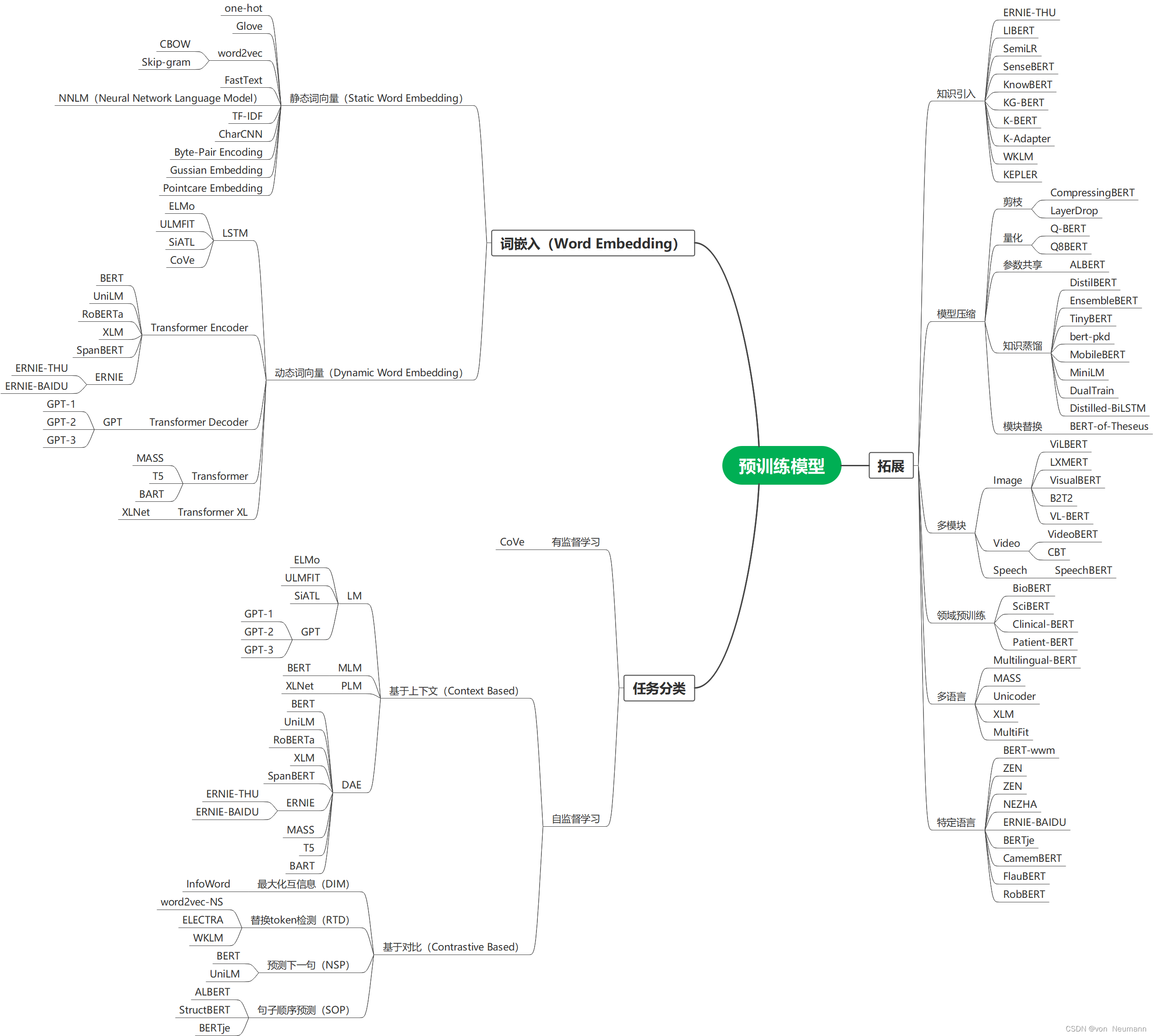
自然语言处理从入门到应用——预训练模型总览:预训练模型的拓展
分类目录:《自然语言处理从入门到应用》总目录 从大量无标注数据中进行预训练使许多自然语言处理任务获得显著的性能提升。总的来看,预训练模型的优势包括:
在庞大的无标注数据上进行预训练可以获取更通用的语言表示,并有利于下游…
CV计算机视觉每日开源代码Paper with code速览-2023.11.15
点击CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:CNN】PadChannel: Improving CNN Performance through Explicit Padding Encoding 论文地址:https:/…
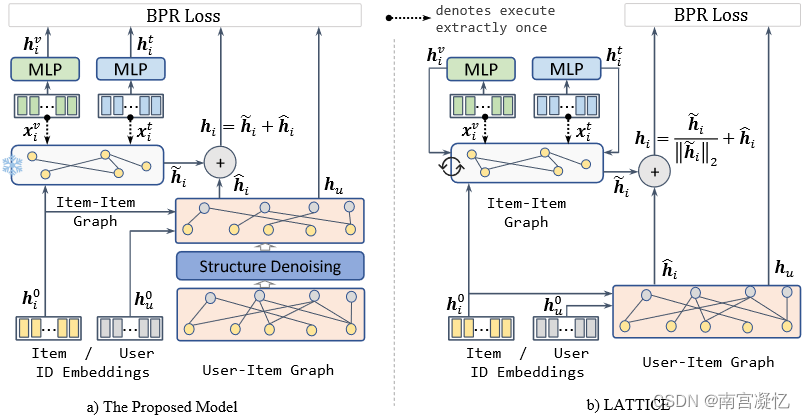
多模态推荐系统综述:四、模型优化
四、模型优化
由于多模态信息的存在,当多模态编码器和推荐模型一起训练时,模型训练的计算要求大大增加。因此,多模态推荐模型在训练过程中可以分为两类:端到端训练和两步训练。 端到端训练可以利用反向传播获得的每个梯度来更新模…
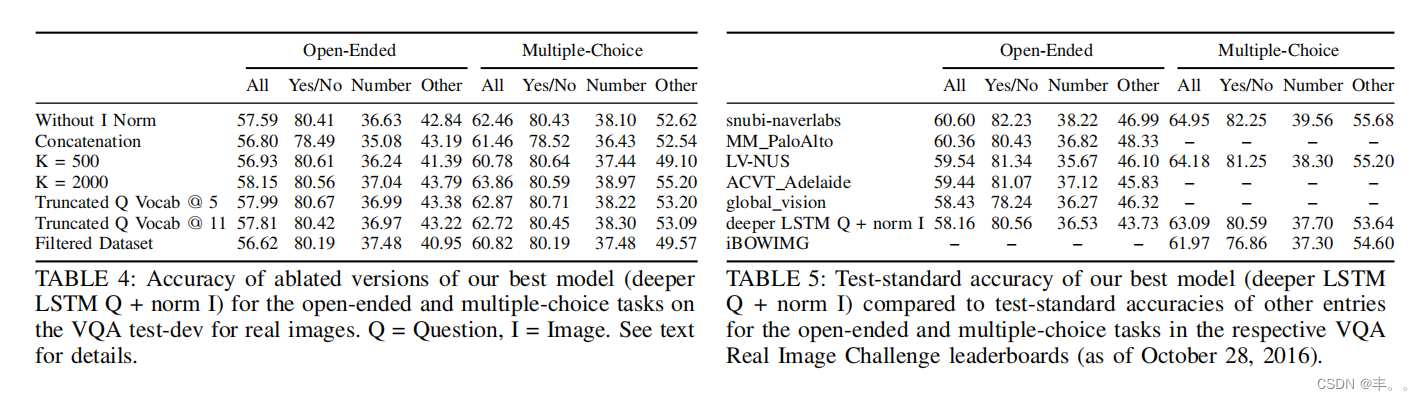
深度学习神经网络学习笔记-多模态方向-09-VQA: Visual Question Answering
摘要
-我们提出了自由形式和开放式视觉问答(VQA)的任务。给定一张图像和一个关于图像的自然语言问题,任务是提供一个准确的自然语言答案。镜像现实场景,比如帮助视障人士,问题和答案都是开放式的。视觉问题有选择地针对图像的不同区域&#…
CVPR 2018 基于累积注意力的视觉定位 Visual Grounding via Accumulated Attention 详解
Abstract: VG面临的主要挑战有3个:1 )查询的主要焦点是什么;2 )如何理解图像;3 )如何定位物体。 在本文中,我们将这些挑战形式化为三个注意力问题,并提出了一个累积注意力( A-ATT )机制来共同推理其中的挑战…
用通俗易懂的方式讲解:使用 Mistral-7B 和 Langchain 搭建基于PDF文件的聊天机器人
在本文中,使用LangChain、HuggingFaceEmbeddings和HuggingFace的Mistral-7B LLM创建一个简单的Python程序,可以从任何pdf文件中回答问题。
一、LangChain简介
LangChain是一个在语言模型之上开发上下文感知应用程序的框架。LangChain使用带prompt和few…
用通俗易懂的方式讲解大模型:在 CPU 服务器上部署 ChatGLM3-6B 模型
大语言模型(LLM)的量化技术可以大大降低 LLM 部署所需的计算资源,模型量化后可以将 LLM 的显存使用量降低数倍,甚至可以将 LLM 转换为完全无需显存的模型,这对于 LLM 的推广使用来说是非常有吸引力的。
本文将介绍如何…

多模态——使用stable-video-diffusion将图片生成视频
多模态——使用stable-video-diffusion将图片生成视频 0. 内容简介1. 运行环境2. 模型下载3. 代码梳理3.1 修改yaml文件中的svd路径3.2 修改DeepFloyDataFiltering的vit路径3.3 修改open_clip的clip路径3.4 代码总体结构 4. 资源消耗5. 效果预览 0. 内容简介
近期,…

GPT-4V被超越?SEED-Bench多模态大模型测评基准更新
📖 技术报告 SEED-Bench-1:https://arxiv.org/abs/2307.16125 SEED-Bench-2:https://arxiv.org/abs/2311.17092 🤗 测评数据 SEED-Bench-1:https://huggingface.co/datasets/AILab-CVC/SEED-Bench SEED-Bench-2&…
【论文精读】HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face 前言Abstract1 Introduction2 Related Works3 HuggingGPT3.1 Task PlanningSpecification-based InstructionDemonstration-based Parsing 3.2 Model SelectionIn-context Task-model Assignment 3…
深度学习:多模态与跨模态
1 定义
1.1 多模态学习
多模态学习(Multimodal Learning)是一种利用来自多种不同感官或交互方式的数据进行学习的方法。在这个语境中,“模态”指的是不同类型的数据输入,如文本、图像、声音、视频等。多模态学习的关键在于整合和…

【Transformer系列论文】TransFuser:端到端自动驾驶的多模态融合Transformer
Article
作者:Aditya Prakash, Kashyap Chitta, Andreas Geiger文献题目:TransFuser:端到端自动驾驶的多模态融合Transformer文献时间:2021文献链接:https://arxiv.org/abs/2104.09224
摘要
互补传感器的表征应该如…

RIS 系列:TransVG: End-to-End Visual Grounding with Transformers 论文阅读笔记
RIS 系列:TransVG: End-to-End Visual Grounding with Transformers 论文阅读笔记 一、Abstract二、引言三、相关工作3.1 视觉定位两阶段方法单阶段方法 3.2 Transformer视觉任务中的 Transformer视觉-语言任务中的 Transformer 四、视觉定位中的 Transformer4.1 基…